Inicio Sesión 1 Sesión 2 Sesión 3 Sesión 4 Sesión 5 Ejercicios
En la actualidad, la reproducibilidad de nuestros resultados ocupa un lugar cada vez más importante por tres razones:
Naturalmente, el estilo adoptado en el establecimiento de un flujo de trabajo tiene mucho de personal. No obstante, existen buenas prácticas y propuestas muy sólidas que podemos adoptar y de las que podemos aprender y, por qué no, incluso tratar de mejorar.
A continuación, nos centraremos en dos flujos de trabajo, uno de ellos, para aquellos que emplean Microsoft Word y otro, más avanzado y con un grado mucho mayor de automatización, para los que prefieren LaTeX. Como referencias generales sobre el tema podemos citar los trabajos de Christensen & Miguel (2018) y Orozco et al. (2018).
Stata +
Microsof Excel + Microsoft Word
Existen varios comandos y paquetes que nos permiten exportar nuestros
resultados a Microsoft Word (o Microsoft Excel). Algunos ejemplos son
estout (que emplearemos posteriormente) y
outreg. Sin embargo, el formato en el que obtenemos estos
resultados, aunque puede ser adecuado para explorar los resultados
preliminares de nuestro trabajo, no se acerca a los estándares de forma
necesarios para la publicación. En otras palabras, nos va a obligar a un
trabajo adicional importante. Si tenemos que repetir el análisis con
alguna modificación, vamos a tener que realizar ese esfuerzo nuevamente.
Podemos encontrar información detallada sobre estout en
varios artículos de su autor (Jann, 2005, 2016) y en la página web dedicada
al paquete por este académico. En particular, para esta tarea vamos a
emplear el comando esttab que incluye este paquete.
. // Fijamos el directorio de trabajo
.
. cd "D:\Dropbox\curso_stata\sesión5"
D:\Dropbox\curso_stata\sesión5
.
. // Instalamos el paquete estout
.
. ssc install estout, replace
checking estout consistency and verifying not already installed...
all files already exist and are up to date.
.
. // Abrimos el archivo
.
. use "ecv18t.dta", clear
(ECV 2018 (mercado de trabajo))
.
. // Creamos las variables necesarias
.
. generate edad2 = edad^2
. label variable edad2 "Edad al cuadrado"
.
. // Realizamos las regresiones
.
. eststo total: regress logsalario ib1.sexo edad edad2 ib1.educg
Source │ SS df MS Number of obs = 11,599
─────────────┼────────────────────────────────── F(5, 11593) = 577.13
Model │ 1600.34458 5 320.068916 Prob > F = 0.0000
Residual │ 6429.36841 11,593 .554590565 R-squared = 0.1993
─────────────┼────────────────────────────────── Adj R-squared = 0.1990
Total │ 8029.713 11,598 .692336006 Root MSE = .74471
─────────────┬────────────────────────────────────────────────────────────────
logsalario │ Coefficient Std. err. t P>|t| [95% conf. interval]
─────────────┼────────────────────────────────────────────────────────────────
sexo │
Mujer │ -.2365705 .01394 -16.97 0.000 -.2638953 -.2092458
edad │ .0721823 .0046198 15.62 0.000 .0631268 .0812378
edad2 │ -.0005808 .0000535 -10.86 0.000 -.0006856 -.0004759
│
educg │
Nivel medio │ .240602 .0185962 12.94 0.000 .2041503 .2770537
Nivel alto │ .613554 .0163944 37.42 0.000 .5814181 .6456898
│
_cons │ 5.145524 .0958254 53.70 0.000 4.95769 5.333357
─────────────┴────────────────────────────────────────────────────────────────
. eststo male: regress logsalario edad edad2 ib1.educg if sexo == 1
Source │ SS df MS Number of obs = 5,966
─────────────┼────────────────────────────────── F(4, 5961) = 386.62
Model │ 833.616132 4 208.404033 Prob > F = 0.0000
Residual │ 3213.21346 5,961 .539039333 R-squared = 0.2060
─────────────┼────────────────────────────────── Adj R-squared = 0.2055
Total │ 4046.8296 5,965 .678429102 Root MSE = .73419
─────────────┬────────────────────────────────────────────────────────────────
logsalario │ Coefficient Std. err. t P>|t| [95% conf. interval]
─────────────┼────────────────────────────────────────────────────────────────
edad │ .0758506 .0061639 12.31 0.000 .0637672 .087934
edad2 │ -.0005995 .0000715 -8.38 0.000 -.0007397 -.0004593
│
educg │
Nivel medio │ .2544457 .0246757 10.31 0.000 .2060723 .3028191
Nivel alto │ .5653884 .0220473 25.64 0.000 .5221677 .6086091
│
_cons │ 5.037839 .127506 39.51 0.000 4.787881 5.287797
─────────────┴────────────────────────────────────────────────────────────────
. eststo female: regress logsalario edad edad2 ib1.educg if sexo == 2
Source │ SS df MS Number of obs = 5,633
─────────────┼────────────────────────────────── F(4, 5628) = 309.16
Model │ 703.432328 4 175.858082 Prob > F = 0.0000
Residual │ 3201.40011 5,628 .56883442 R-squared = 0.1801
─────────────┼────────────────────────────────── Adj R-squared = 0.1796
Total │ 3904.83244 5,632 .693329624 Root MSE = .75421
─────────────┬────────────────────────────────────────────────────────────────
logsalario │ Coefficient Std. err. t P>|t| [95% conf. interval]
─────────────┼────────────────────────────────────────────────────────────────
edad │ .0665724 .00695 9.58 0.000 .0529477 .080197
edad2 │ -.0005401 .0000803 -6.73 0.000 -.0006974 -.0003827
│
educg │
Nivel medio │ .2314164 .0282288 8.20 0.000 .176077 .2867557
Nivel alto │ .6600433 .0245986 26.83 0.000 .6118206 .7082661
│
_cons │ 5.05201 .1443795 34.99 0.000 4.768971 5.33505
─────────────┴────────────────────────────────────────────────────────────────
.
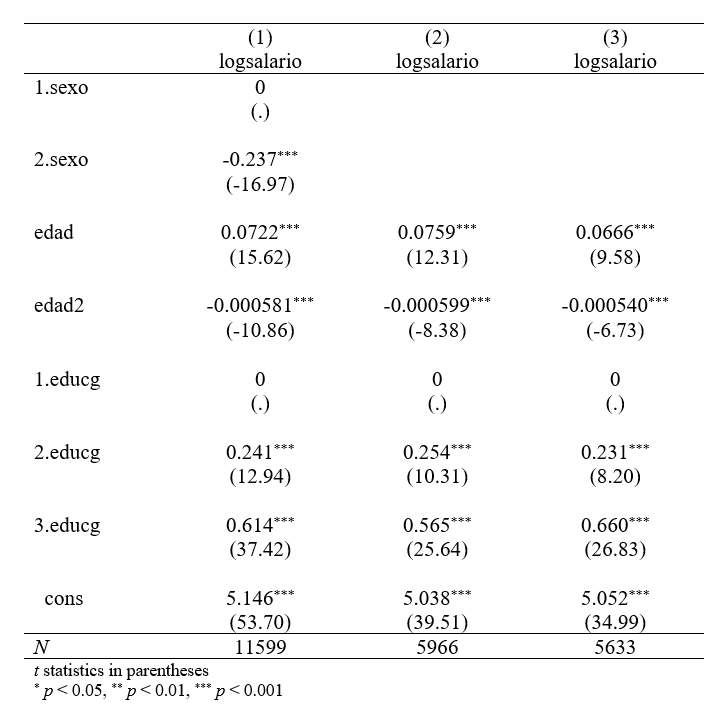
. esttab total male female using "salarios1.rtf", replace
(output written to salarios1.rtf)
Obtenemos la siguiente tabla en Microsoft Word:
Empleando algunas opciones adicionales de estout,
podemos mejorar el resultado.
. esttab total male female using "salarios2.rtf", ///
> b(%04,3fc) se(%04,3fc) /// Presentar coeficientes y errores estándar (con formato)
> varlabels(2.sexo "Mujer" edad "Edad" edad2 "Edad{\super 2}" 2.educg "Educación media" 3.educg "Educación superior") /// Etiquetas
> stats(N r2_a, fmt(%6,0fc %04,3fc) labels("No. de observaciones" "R{\super 2} ajustado")) ///
> nobaselevels /// No mostrar las categorías de referencia
> noconstant /// No mostrar la constante
> varwidth(20) /// Anchura de la columna de la variable
> substitute("\deflang1033\plain\fs24" "\deflang1033\plain\fs20") ///
> fonttbl(\f0\fnil Times New Roman;\f1\fnil Times New Roman;) /// Tamaño de la fuente
> title(\fs24{\b Tabla 1.} {Regresión salarial por sexo}) /// Título de la tabla
> nonumbers mtitles("Total" "Hombres" "Mujeres") /// Títulos de las columnas
> nonotes /// Eliminar las notas por defecto
> addnote("*** significativo al 1%; ** significativo al 5%; significativo al 10%. Errores estándar entre paréntesis. Todos los modelos incluyen una constante." ///
> "Fuente: Elaboración propia a partir de la ECV 2018.") ///
> replace
(output written to salarios2.rtf)
La versión 17 y posteriores de Stata aceptan caracteres
Unicode. Para versiones anterioes a la 17, podemos convertir el archivo
.docx para que este aparezca con los caracteres Unicode de
la siguiente forma:
. unicode convertfile "salarios2.rtf" "salarios2_unicode.rtf", dstencoding(ISO-8859-1) replace // Posibilidad de utilizar caracteres que no son unicode note: file "salarios2.rtf" converted to file "salarios2_unicode.rtf"
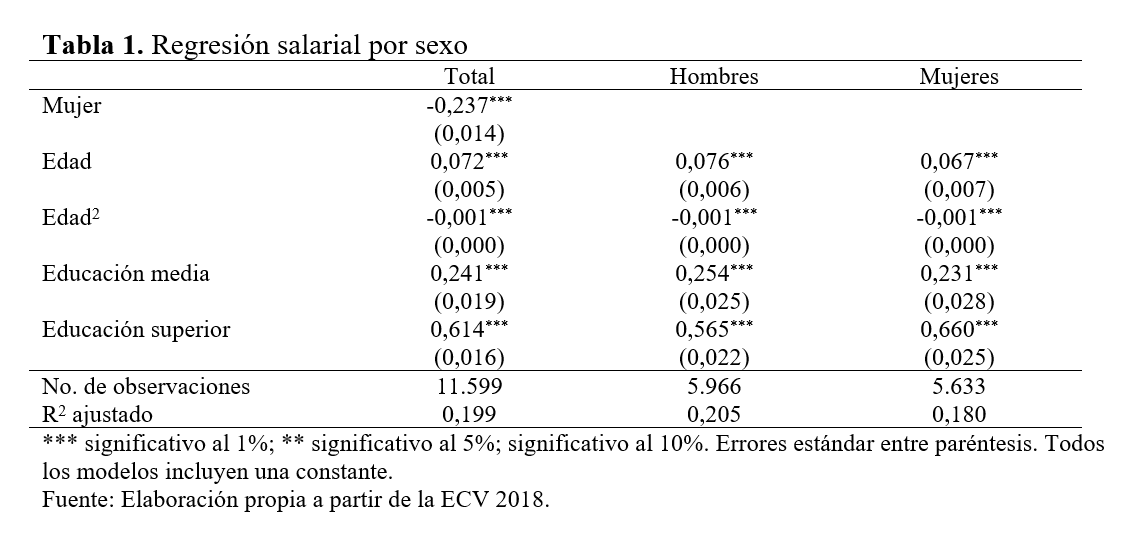
Desafortunadamente, existen todavía varias opciones sobre las que no
tenemos control. De esta forma, si hay un cambio en la tabla, tenemos
que copiar la tabla desde el documento .rtf y pegar la
tabla en el documento donde estemos escribiendo el artículo
(.docx). Si, por ejemplo, necesitamos cambiar el tamaño de
la fuente, añadir o suprimir líneas horizontales o cambiar la alineación
de las celdas, tendremos que hacerlo manualmente cada vez que hagamos
esta operación.
Una forma de mejorar ligeramente el flujo de trabajo es exportar la
tabla, con muchas más opciones de formato en Microsft Excel y,
posteriomente, copiar y pegar en el documento. A través del comando
putexcel, Stata puede cambiar el formato de
las celdas de la hoja de cálculo. El proceso es más lento y “artesanal”,
pero, en el medio plazo, ahorraremos tiempo.
// Creamos las dummies manualmente
. tabulate educg, generate(educdummy)
. tabulate sexo, generate(sexodummy)
// Realizamos la primera regresión
. regress logsalario sexodummy2 edad edad2 educdummy2 educdummy3
// Configuramos una hoja de cálculo a la que exportar los resultados
. putexcel set "salarios.xlsx", replace sheet("tabla 1")
. putexcel (A1:Z100), vcenter font(timesnewroman, 10)
. putexcel A1 = "Tabla 1. Regresión salarial por sexo", left vcenter font(timesnewroman, 12)
. putexcel B2 = ("Total"), right vcenter font(timesnewroman, 10)
. putexcel D2 = ("Hombres"), right vcenter font(timesnewroman, 10)
. putexcel F2 = ("Mujeres"), right vcenter font(timesnewroman, 10)
. local k = e(rank) - 1
. matrix R = r(table)
. matrix b = R[1,1...]
. matrix se = R[2,1...]
. matrix p = R[4,1...]
. scalar r2_a = e(r2_a)
. scalar N = e(N)
. putexcel A3 = ("Mujer"), left vcenter font(timesnewroman, 10)
. putexcel A5 = ("Edad"), left vcenter font(timesnewroman, 10)
. putexcel A7 = ("Edad al cuadrado"), left vcenter font(timesnewroman, 10)
. putexcel A9 = ("Educación media"), left vcenter font(timesnewroman, 10)
. putexcel A11 = ("Educación alta"), left vcenter font(timesnewroman, 10)
. putexcel A14 = ("No. de observaciones"), left vcenter font(timesnewroman, 10)
. putexcel A15 = ("R2 ajustado"), left vcenter font(timesnewroman, 10)
. forvalues i = 1(1)`k' {
2. putexcel B`=1+2*`i'' = (b[1,`i']), nformat(0.000) right vcenter font(timesnewroman, 10)
3. putexcel B`=2+2*`i'' = (se[1,`i']), nformat((0.000)) right vcenter font(timesnewroman, 10)
4. if p[1,`i'] < 0.1 {
5. putexcel C`=1+2*`i'' = ("*"), left vcenter font(timesnewroman, 10)
6. }
7. if p[1,`i'] < 0.05 {
8. putexcel C`=1+2*`i'' = ("**"), left vcenter font(timesnewroman, 10)
9. }
10. if p[1,`i'] < 0.01 {
11. putexcel C`=1+2*`i'' = ("***"), left vcenter font(timesnewroman, 10)
12. }
13. }
. putexcel B`=4 + 2*`k'' = N, nformat(#,###) right vcenter font(timesnewroman, 10)
. putexcel B`=5 + 2*`k'' = r2_a, nformat(0.000) right vcenter font(timesnewroman, 10)
. putexcel A`=7 + 2*`k'' = "Notas: *** significativo al 1%; ** significativo al 5%; significativo al 10%. Errores estándar entre paréntesis. Todos los modelos incluyen una constante.", left vcenter font(timesnewroman, 10)
. putexcel A`=8 + 2*`k'' = "Fuente: Elaboración propia a partir de la ECV2018", left vcenter font(timesnewroman, 10)
// Repetimos el procedimiento con los hombres
. regress logsalario edad edad2 educdummy2 educdummy3 if sexo == 1
. local k = e(rank) - 1
. matrix R = r(table)
. matrix b = R[1,1...]
. matrix se = R[2,1...]
. matrix p = R[4,1...]
. scalar r2_a = e(r2_a)
. scalar N = e(N)
. forvalues i = 1(1)`k' {
2. putexcel D`=3+2*`i'' = (b[1,`i']), nformat(0.000) right vcenter font(timesnewroman, 10)
3. putexcel D`=4+2*`i'' = (se[1,`i']), nformat((0.000)) right vcenter font(timesnewroman, 10)
4. if p[1,`i'] < 0.1 {
5. putexcel E`=3+2*`i'' = ("*"), left vcenter font(timesnewroman, 10)
6. }
7. if p[1,`i'] < 0.05 {
8. putexcel E`=3+2*`i'' = ("**"), left vcenter font(timesnewroman, 10)
9. }
10. if p[1,`i'] < 0.01 {
11. putexcel E`=3+2*`i'' = ("***"), left vcenter font(timesnewroman, 10)
12. }
13. }
. putexcel D`=6 + 2*`k'' = N, nformat(#,###) right vcenter font(timesnewroman, 10)
. putexcel D`=7 + 2*`k'' = r2_a, nformat(0.000) right vcenter font(timesnewroman, 10)
// Repetimos el procedimiento con las mujeres
. regress logsalario edad edad2 educdummy2 educdummy3 if sexo == 2
. local k = e(rank) - 1
. matrix R = r(table)
. matrix b = R[1,1...]
. matrix se = R[2,1...]
. matrix p = R[4,1...]
. scalar r2_a = e(r2_a)
. scalar N = e(N)
. forvalues i = 1(1)`k' {
2. putexcel F`=3+2*`i'' = (b[1,`i']), nformat(0.000) right vcenter font(timesnewroman, 10)
3. putexcel F`=4+2*`i'' = (se[1,`i']), nformat((0.000)) right vcenter font(timesnewroman, 10)
4. if p[1,`i'] < 0.1 {
5. putexcel G`=3+2*`i'' = ("*"), left vcenter font(timesnewroman, 10)
6. }
7. if p[1,`i'] < 0.05 {
8. putexcel G`=3+2*`i'' = ("**"), left vcenter font(timesnewroman, 10)
9. }
10. if p[1,`i'] < 0.01 {
11. putexcel G`=3+2*`i'' = ("***"), left vcenter font(timesnewroman, 10)
12. }
13. }
. putexcel F`=6 + 2*`k'' = N, nformat(#,###) right vcenter font(timesnewroman, 10)
. putexcel F`=7 + 2*`k'' = r2_a, nformat(0.000) right vcenter font(timesnewroman, 10)
// Cerramos la sesión de putexcel
. putexcel closePara implementar esta estrategia, primero, creamos en nuestro
documento de MS Word el esqueleto de la tabla. En segundo lugar,
copiamos las celdas con la información estadística del archivo de MS
Excel. Por último, pegamos las celdas copiadas en el documento de MS
Word mediante la opción del menú Pegado especial \(\rightarrow\) Formato RTF. Es
un método lento, pero muy flexible, que puede ser ideal para
proporcionar los resultados a los evaluadores y conseguir la
reproducibilidad total.
Stata + LaTeX
Una opción excelente para configurar nuestro flujo de trabajo es
utilizar LaTeX para
escribir nuestros textos. Es un sistema de composición de textos de
código abierto que emplea comandos de TeX, un lenguaje de nivel bajo con
comandos muy elementales. La principal desventaja de LaTeX es que no se
trata de un procesador WYSIWYG (“lo que ves es lo que obtienes”), sino
que se basa en instrucciones. Esto implica que el contenido está
separado de la forma, lo cual puede ser una ventaja. Como el contenido
es básicamente texto plano, podemos integrar output en texto plano que
obtengamos de otros programas, como Stata. La gran ventaja
de LaTeX es la altísima calidad de los documentos, especialmente
apreciable en trabajos que requieran el empleo de fórmulas matemáticas.
Por esta razón, es una herramienta de edición profesional. Otras
ventajas, no exclusivas de este sistema, se refieren a la gestión de la
bibliografía.
La integración de Stata y LaTeX en nuestro flujo de
trabajo es sencilla. Requerimos únicamente una distribución y un editor
de TeX y generar resultados e incluso fragmentos de texto que puedan ser
directamente incluidos en LaTeX. Las principales distribuciones de TeX
son MiKTeX y TeX Live. Existen muchos
editores de TeX gratuitos, como TeXstudio, Texmaker o LyX. Mediante alguna herramienta como Dropbox o Google Drive podemos lograr un
muy buen sistema de trabajo reproducible colaborativo.
Otra opción es optar por Overleaf. Se trata un editor online que incorpora la distribución de TeX Live. No requiere instalar ninguna distribución ni editor en nuestro equipo, permite la colaboración en tiempo real (como Google Docs, al contrario que Dropbox) e incluye control de versiones. Existe una versión gratuita, en la que algunas de sus capacidades no están disponibles. Debido a que no requiere instalación local, lo emplearemos en los siguientes ejemplos, aunque hagan que el flujo de trabajo sea menos fluido que con una instalación local, ya que, además, no disponemos de la versión de pago (que incluye la sincronización con Dropbox y GitHub, un sistema de control de versiones que comentaremos en la siguiente sección).
Para poner en marcha este tipo de flujo, vamos a emplear el paquete
estout, mencionado en la sección anterior, y el paquete
texdoc (Jann,
2016), que nos va a permitir crear textos planos con resultados
de Stata que vamos a poder llevar a nuestro editor de
LaTeX. La idea básica es que Stata genere archivos de texto
plano reconocibles por LaTeX y almacenarlos en una carpeta de nuestro
proyecto. Posteriormente, en el editor de LaTeX, utilizaremos el comando
input{} para incluir el archivo generado. La mayor parte
del formato resultante del texto incluido será responsabilidad de LaTeX,
que habremos configurado previamente. En general, mi consejo es
únicamente crear en Stata de las filas con la información
estadística y diseñar el resto de la tabla en el editor de LaTeX.
. // Establecemos la coma como decimal
.
. set dp comma
.
. // Realizamos las regresiones
.
. eststo total: quietly: regress logsalario sexodummy2 edad edad2 educdummy2 educdummy3
. eststo male: quietly: regress logsalario edad edad2 educdummy2 educdummy3 if sexo == 1
. eststo female: quietly: regress logsalario edad edad2 educdummy2 educdummy3 if sexo == 2
.
. // Exportamos la tabla
.
. estout total male female using "tabla1.tex", replace style(tex) ///
> keep(sexodummy2 edad edad2 educdummy2 educdummy3) ///
> varlabels(sexodummy2 "Mujer" edad "Edad" edad2 "Edad\textsuperscript{2}" educdummy2 "Educación media" educdummy3 "Educación superior") ///
> cells(b(fmt(3) star) se(par fmt(3))) ///
> starlevels("\sym{*}" 0.10 "\sym{**}" 0.05 "\sym{***}" 0.01) ///
> stats(N r2_a, fmt(%6.0f %04,3fc) labels("No. de observaciones" "R\textsuperscript{2} ajustado")) ///
> prefoot("[2ex]") ///
> mlabel(, none) collabels(none)
(output written to tabla1.tex)
Podemos ver que la tabla de LaTeX generada es extremadamente simple.

A continuación, calculamos unos estadísticos descriptivos, los
almacenamos en macros y exportamos un texto que las contiene al archivo
texto.tex
. // Instalamos el paquete texdoc
.
. ssc install texdoc, replace
checking texdoc consistency and verifying not already installed...
all files already exist and are up to date.
.
. // Creamos algunas macros con estadísticos descriptivos
.
. summarize salario if sexo == 1
Variable │ Obs Mean Std. dev. Min Max
─────────────┼─────────────────────────────────────────────────────────
salario │ 6.036 2163,165 1926,792 0 46507,3
. local salh: display %04.0fc r(mean)
. summarize salario if sexo == 2
Variable │ Obs Mean Std. dev. Min Max
─────────────┼─────────────────────────────────────────────────────────
salario │ 5.708 1830,543 1657,196 0 62207
. local salm: display %04.0fc r(mean)
.
. // Exportamos un texto que contiene las macros
.
. texdoc init "texto.tex", replace force
(texdoc output file is texto.tex)
. tex El salario medio de los hombres es \num{`salh'} euros mensuales y el de las mujeres, \num{`salm'}.
. texdoc close
(texdoc output written to texto.tex)
.

Por último, podemos generar un gráfico en formato .pdf,
que es muy apropiado para exportar a LaTeX.
. // Configuramos el gráfico
.
. grstyle clear
. grstyle init
. grstyle set plain
. grstyle color background white
. grstyle graphsize x 4
. grstyle graphsize y 4
. grstyle set nogrid
. grstyle set color hue, n(4)
. grstyle linestyle legend none
. grstyle set legend 6
. grstyle set color red green orange blue
.
. // Elaboramos el gráfico
.
. twoway ///
> (kdensity logsalario if sexo == 1 [aweight = peso]) ///
> (kdensity logsalario if sexo == 2 [aweight = peso]), ///
> ytitle("Densidad", size(vsmall) margin(sides)) ylabel(, labsize(vsmall) format(%02,1fc)) ///
> xtitle("Salario bruto en logaritmos (euros/mes)", size(vsmall) margin(top_bottom)) xlabel(, labsize(vsmall)) ///
> legend(on order(1 "Hombres" 2 "Mujeres") cols(1) size(vsmall) position(10) ring(0))
.
. // Exportamos el gráfico
.
. graph export "figura1.pdf", as(pdf) replace
file figura1.pdf saved as PDF format
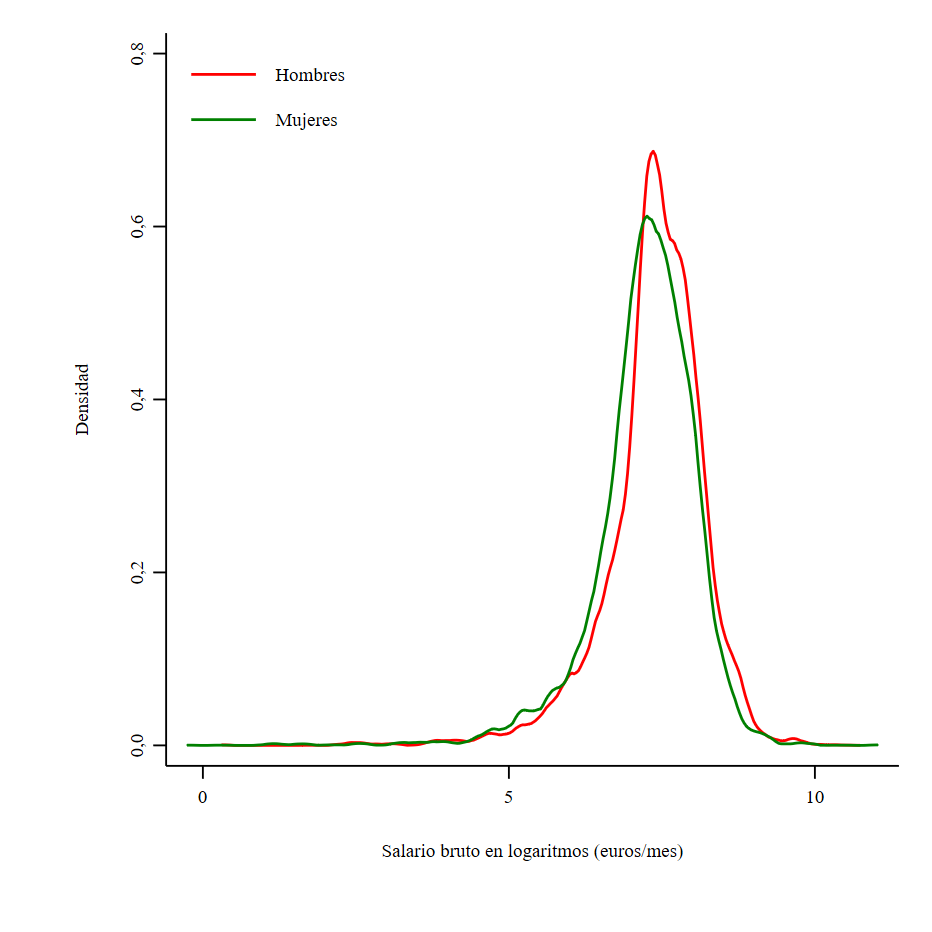
A continuación, en nuestro editor de LaTeX, donde habremos preparado
el espacio para incluir los elementos generados, incluimos los archivos
anteriores con el comando \input{} para la tabla y el texto
e \includegraphics{} para la figura en .pdf.
Como en este ejemplo estamos usando Overleaf (y no disponemos de sus
características de pago), tenemos que subir los archivos a la carpeta
correspondiente en la aplicación. Si utilizásemos un editor instalado
localmente, simplemente, en el archivo .tex nos
referiríamos a su ruta local de la tabla, el texto y los gráficos. El
archivo principal, que representa contiene nuestro documento, se llama
main.tex.
Por último, cabe mencionar la facilidad de gestión de referencias bibliográficas con programas gratuitos como JabRef, Mendeley o Zotero, que pueden utilizarse, además, con otro tipo de aplicaciones para procesar textos. Los recursos disponibles en la red para el aprendizaje de LaTeX, que es, fundamentalmente, un proceso learning by doing, son realmente inabarcables. Una buena referencia inicial para Ciencias Sociales podría ser Frain (2014).
StataDesde la versión 17, de Stata permite crear tablas
personalizadas de resultados y exportarlas posteriormente en distintos
formatos (e.g., archivos .docx, .xlsx o
.tex). Para llevar a cabo esta tarea, empleamos el comando
collect. Dado que resulta bastante complejo, como en el
caso de los gráficos, una forma de trabajo interesante de elaborar este
tipo de tablas consiste en combinar los comandos con el sistema de
ventanas. Al margen de este consejo sobre la forma de elaborar las
tablas, en el blog
oficial de Stata se ofrecen buenos consejos sobre el
tema basados en la línea de comandos.
Así, en primer lugar, podemos almacenar la información de los modelos
con collect.
. // Creación de tablas con la herramienta Tables Builder de Stata
.
. collect clear
. collect create Salarios
(current collection is Salarios)
.
. collect _r_b _r_se, tag(model[Total]): regress logsalario ib1.sexo edad edad2 ib1.educg
Source │ SS df MS Number of obs = 11.599
─────────────┼────────────────────────────────── F(5, 11593) = 577,13
Model │ 1600,34458 5 320,068916 Prob > F = 0,0000
Residual │ 6429,36841 11.593 ,554590565 R-squared = 0,1993
─────────────┼────────────────────────────────── Adj R-squared = 0,1990
Total │ 8029,713 11.598 ,692336006 Root MSE = ,74471
─────────────┬────────────────────────────────────────────────────────────────
logsalario │ Coefficient Std. err. t P>|t| [95% conf. interval]
─────────────┼────────────────────────────────────────────────────────────────
sexo │
Mujer │ -,2365705 ,01394 -16,97 0,000 -,2638953 -,2092458
edad │ ,0721823 ,0046198 15,62 0,000 ,0631268 ,0812378
edad2 │ -,0005808 ,0000535 -10,86 0,000 -,0006856 -,0004759
│
educg │
Nivel medio │ ,240602 ,0185962 12,94 0,000 ,2041503 ,2770537
Nivel alto │ ,613554 ,0163944 37,42 0,000 ,5814181 ,6456898
│
_cons │ 5,145524 ,0958254 53,70 0,000 4,95769 5,333357
─────────────┴────────────────────────────────────────────────────────────────
. collect _r_b _r_se, tag(model[Hombres]): regress logsalario edad edad2 ib1.educg if sexo == 1
Source │ SS df MS Number of obs = 5.966
─────────────┼────────────────────────────────── F(4, 5961) = 386,62
Model │ 833,616132 4 208,404033 Prob > F = 0,0000
Residual │ 3213,21346 5.961 ,539039333 R-squared = 0,2060
─────────────┼────────────────────────────────── Adj R-squared = 0,2055
Total │ 4046,8296 5.965 ,678429102 Root MSE = ,73419
─────────────┬────────────────────────────────────────────────────────────────
logsalario │ Coefficient Std. err. t P>|t| [95% conf. interval]
─────────────┼────────────────────────────────────────────────────────────────
edad │ ,0758506 ,0061639 12,31 0,000 ,0637672 ,087934
edad2 │ -,0005995 ,0000715 -8,38 0,000 -,0007397 -,0004593
│
educg │
Nivel medio │ ,2544457 ,0246757 10,31 0,000 ,2060723 ,3028191
Nivel alto │ ,5653884 ,0220473 25,64 0,000 ,5221677 ,6086091
│
_cons │ 5,037839 ,127506 39,51 0,000 4,787881 5,287797
─────────────┴────────────────────────────────────────────────────────────────
. collect _r_b _r_se, tag(model[Mujeres]): regress logsalario edad edad2 ib1.educg if sexo == 2
Source │ SS df MS Number of obs = 5.633
─────────────┼────────────────────────────────── F(4, 5628) = 309,16
Model │ 703,432328 4 175,858082 Prob > F = 0,0000
Residual │ 3201,40011 5.628 ,56883442 R-squared = 0,1801
─────────────┼────────────────────────────────── Adj R-squared = 0,1796
Total │ 3904,83244 5.632 ,693329624 Root MSE = ,75421
─────────────┬────────────────────────────────────────────────────────────────
logsalario │ Coefficient Std. err. t P>|t| [95% conf. interval]
─────────────┼────────────────────────────────────────────────────────────────
edad │ ,0665724 ,00695 9,58 0,000 ,0529477 ,080197
edad2 │ -,0005401 ,0000803 -6,73 0,000 -,0006974 -,0003827
│
educg │
Nivel medio │ ,2314164 ,0282288 8,20 0,000 ,176077 ,2867557
Nivel alto │ ,6600433 ,0245986 26,83 0,000 ,6118206 ,7082661
│
_cons │ 5,05201 ,1443795 34,99 0,000 4,768971 5,33505
─────────────┴────────────────────────────────────────────────────────────────
.
. collect layout (colname[2.sexo edad edad2 2.educg 3.educg]#result[_r_b _r_se] result[N r2_a]) (model[Total] model[Hombres] model[Mujeres]) (), name(Salarios)
Collection: Salarios
Rows: colname[2.sexo edad edad2 2.educg 3.educg]#result[_r_b _r_se] result[N r2_a]
Columns: model[Total] model[Hombres] model[Mujeres]
Table 1: 17 x 3
───────────────────────┬──────────────────────────────
│ Total Hombres Mujeres
───────────────────────┼──────────────────────────────
Mujer │
Coefficient │ -,2365705
Std. error │ ,01394
Edad │
Coefficient │ ,0721823 ,0758506 ,0665724
Std. error │ ,0046198 ,0061639 ,00695
Edad al cuadrado │
Coefficient │ -,0005808 -,0005995 -,0005401
Std. error │ ,0000535 ,0000715 ,0000803
Nivel medio │
Coefficient │ ,240602 ,2544457 ,2314164
Std. error │ ,0185962 ,0246757 ,0282288
Nivel alto │
Coefficient │ ,613554 ,5653884 ,6600433
Std. error │ ,0163944 ,0220473 ,0245986
Number of observations │ 11599 5966 5633
Adjusted R-squared │ ,1989575 ,2054596 ,1795614
───────────────────────┴──────────────────────────────
Posteriormente, empleamos el sistema de ventanas para personalizar la tabla.
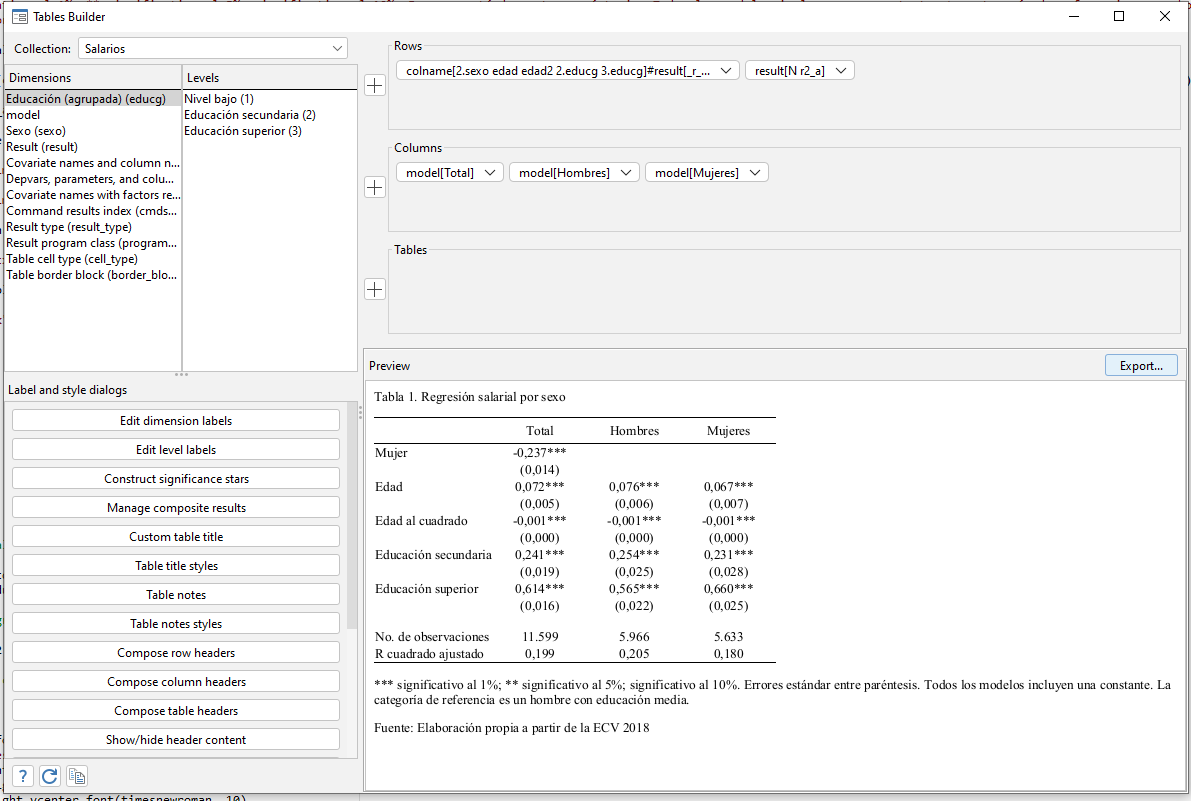
Mediante el método ensayo-error, vamos adecuando la tabla a nuestras
preferencias. Cada modificación resulta en un comando, que podremos
copiar a nuestro archivo .do para reproducir el gráfico
cuando queramos.
. collect stars _r_p 0.010 `"***"' 0.050 `"**"' 0.100 `"*"', attach(_r_b)
. collect label levels result N "No. de observaciones" r2_a "R cuadrado ajustado", modify
. collect style header result[_r_b], level(hide)
. collect style header result[_r_se], level(hide)
. collect style cell result[_r_b _r_se r2_a], warn nformat(%04,3f) halign(center) valign(center)
. collect style cell result[_r_se], warn sformat((%s))
. collect style cell result[N], warn nformat(%6,0fc)
. collect style cell result[N r2_a], warn halign(left) valign(center)
. collect style cell cell_type[item], warn halign(center) valign(center) margin( right, width(15pt) ) margin( left, width(15pt) )
. collect label levels educg 2 "Educación secundaria" 3 "Educación superior", modify
. collect style cell model[Total Hombres Mujeres], warn halign(center) valign(center)
. collect style cell result[N], warn margin( top, width(15) )
. collect title "Tabla 1. Regresión salarial por sexo"
. collect notes, clear
. collect notes `"*** significativo al 1%; ** significativo al 5%; significativo al 10%. Errores estándar entre paréntesis. Todos los modelos incluyen una constante."'
. collect notes `"Fuente: Elaboración propia a partir de la ECV 2018"'
. collect style cell, border( all, pattern(nil) )
. collect style cell cell_type[column-header corner], warn border(top, width(0.5) pattern(single)) border(bottom, width(0.5) pattern(single)) margin(top, width(5)) margin( bottom, width(5) )
. collect style cell result[r2_a], warn border( bottom, width(0.5) pattern(single) )
. collect style cell, basestyle font("Times New Roman", size(10pt))
. collect style title, font("Times New Roman", size(10pt))
. collect style notes, font("Times New Roman", size(10pt))
Una vez que la tabla se adecua a nuestras preferencias, podemos exportarla en distintos formatos.
Por ejemplo, podemos exportarla en MS Word.
. // Exportamos la tabla en MS Word
.
. collect style putdocx, halign(center) width(70%)
. collect export "salarios3.docx", as(docx) dofile("instrucciones_putdocx", replace) replace
(collection Salarios exported to file salarios3.docx)
También puede exportarse en .tex.
. // Exportamos la tabla en TeX . . collect style tex, nobegintable centering . collect export "salarios3.tex", as(tex) replace (collection Salarios exported to file salarios3.tex)
La herramienta de personalización de tablas es sin duda útil y mejora
el programa, pero, actualmente, los flujos anteriores basados en
putexcel en el caso de MS Word y estout
resultan más flexibles.
Una de las últimas novedades en el uso de Stata consiste
en la posibilidad de la elaborar de documentos dinámicos. Se trata de
archivos, normalmente, .docx, .pdf o
.html, que incluyen texto, comandos y resultados. Su
carácter dinámico se explica porque, cuando modificamos los comandos, el
documento resultante refleja los cambios en los resultados. Su principal
utilidad puede ser crear informes preliminares de resultados,
presentaciones, páginas webs sencillas o, incluso, algunas personas lo
utilizan para escribir trabajos de investigación completos. No obstante,
en relación con esta última opción, Stata está lejos
todavía de las posibilidades que ofrece R con
RStudio y knitr (Gandrud, 2020; Xie, 2015).
En el caso de Stata, existen varias opciones para
elaborar documentos dinámicos. La versión 15 de Stata
incorpora esta posibilidad dentro del paquete dyndoc. Sin
embargo, hay otras alternativas creadas por los usuarios. Para generar
todas las páginas webs en las que se ha organizado este curso, por
ejemplo, hemos utilizado el paquete markstat (Rodríguez, 2017). En
mi opinión, esta opción es preferible al paquete oficial porque es mucho
más parecido al lenguaje Markdown. En su página
web, el creador
de markstat, Germán Rodríguez, nos orienta de las
posibilidades de este paquete, con abundantes ejemplos.
En Stata 17, además, existe la posibilidad de integrar
código de Python en
Stata y código de Stata
en Python. Lo mismo aplica a R.
Por último, una tendencia reciente es el empleo de sistemas control
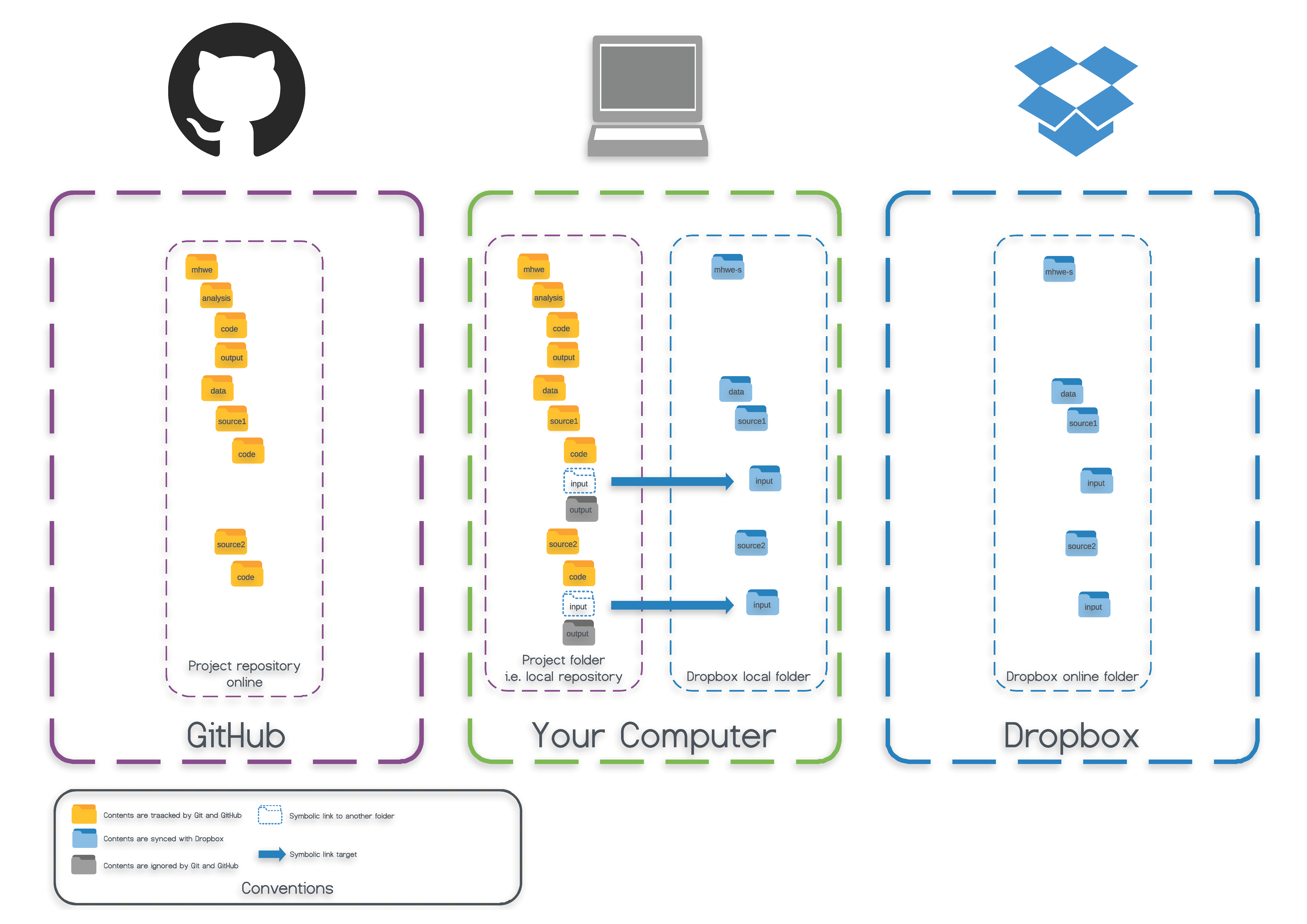
de versiones, como Git, especialmente, a través de la nube
con GitHub. La curva de aprendizaje puede reducirse
sustancialmente instalando GitHub Desktop.
Básicamente, este sistema permite trabajar de manera colaborativa en la
escritura de código. En el caso de Stata, es aplicable, por
lo tanto, a los archivos .do y .ado. Permite
que varias personas trabajen de forma simultánea (e incluso cualquier
usuario puede solicitar contributir) y todos los cambios son
reversibles, pudiendo volver en cualquier momento a la versión que
deseemos. Podemos encontrar una buena introducción en Pellegrina & Fajardo
(2018) y, especialmente, en la guía de Asjad
Naqvi.