StataInicio Sesión 1 Sesión 2 Sesión 3 Sesión 4 Sesión 5 Ejercicios
Stata es un programa de análisis estadístico que
permite manejar bases de datos de gran tamaño. Resulta especialmente
apropiado para tareas relacionadas con la Microeconometría aplicada. Es
especialmente bueno con datos de encuestas.Stata para ilustrar ejemplos y resolver
ejercicios.markstat.Una alternativa muy razonable es R: potente, flexible,
gratuito, con una comunidad de usuarios impresionante, un lenguaje de
programación muy potente y muchas cosas más… pero con una curva de
aprendizaje muchísimo más pronunciada.
El curso consta de 10 horas, por lo que la finalidad es proporcionar
a los asistentes un panorama de lo que Stata puede hacer y
orientarles en la búsqueda de recursos apropiados para que puedan
aprender de forma autónoma de acuerdo con sus intereses. Todos los
materiales del curso pueden descargarse en el siguiente enlace.
Existen varias formas de trabajar con Stata:
Existe un importante número de libros de introducción a Stata, entre los que se pueden destacar los de Acock (2018) y, en español, Escobar et al. (2012).
Stata.dtaSon los archivos de datos de Stata, equivalentes a los
archivos .xlsx en Excel o .sav en SPSS. Es el
formato al que debemos convertir los datos con los que queramos
trabajar.
.doArchivos de sintaxis de comandos, equivalentes a los
.sps en SPSS. Resultan absolutamente básicos, para ahorrar
tiempo (Stata no cuenta con la función deshacer) y
garantizar la reproducibilidad. En realidad, son archivos de texto
plano, idénticos a los .txt.
.smcl o
.logSon archivos de registro, que recogen las operaciones y resultados en
nuestro espacio de trabajo, similares a los archivos .log
en SPSS. Representan una forma razonable de presentar resultados
preliminares a co-autores o una forma de entrega de ejercicios de los
estudiantes. Actualmente, gracias a la integración de Stata
con otros lenguajes y softwares (pdf o html), existen mejores
alternativas.
.gphSon los archivos nativos para las figuras en Stata. En
las últimas versiones, se pueden editar y la flexibilidad se ha
incrementado mucho. Además, es posible generar los gráficos directamente
en formatos de imagen o pdf.
.adoSon macros de Stata, algo más sofisticados que los
archivos .do que contienen comandos programados, rutinas. Hay
un impresionante arsenal de estos archivos creados por usuarios.
.sthlpLos archivos de ayuda de Stata.
.stsemDiagramas de ecuaciones estructurales.
.stmdArchivos Markdown de Stata, similares a los archivos
.do, que se emplean por comandos como markstat
para la creación de documentos dinámicos reproducibles.
.dtasArchivos que contienen frames (varias bases de
datos).
.stprArchivos de proyectos de Stata. Agrupan jerárquicamente
los archivos anteriores.
En la práctica, los archivos que más vamos a utilizar son los
archivos .do y .dta.
StataEl entorno de Stata nos muestra:
.do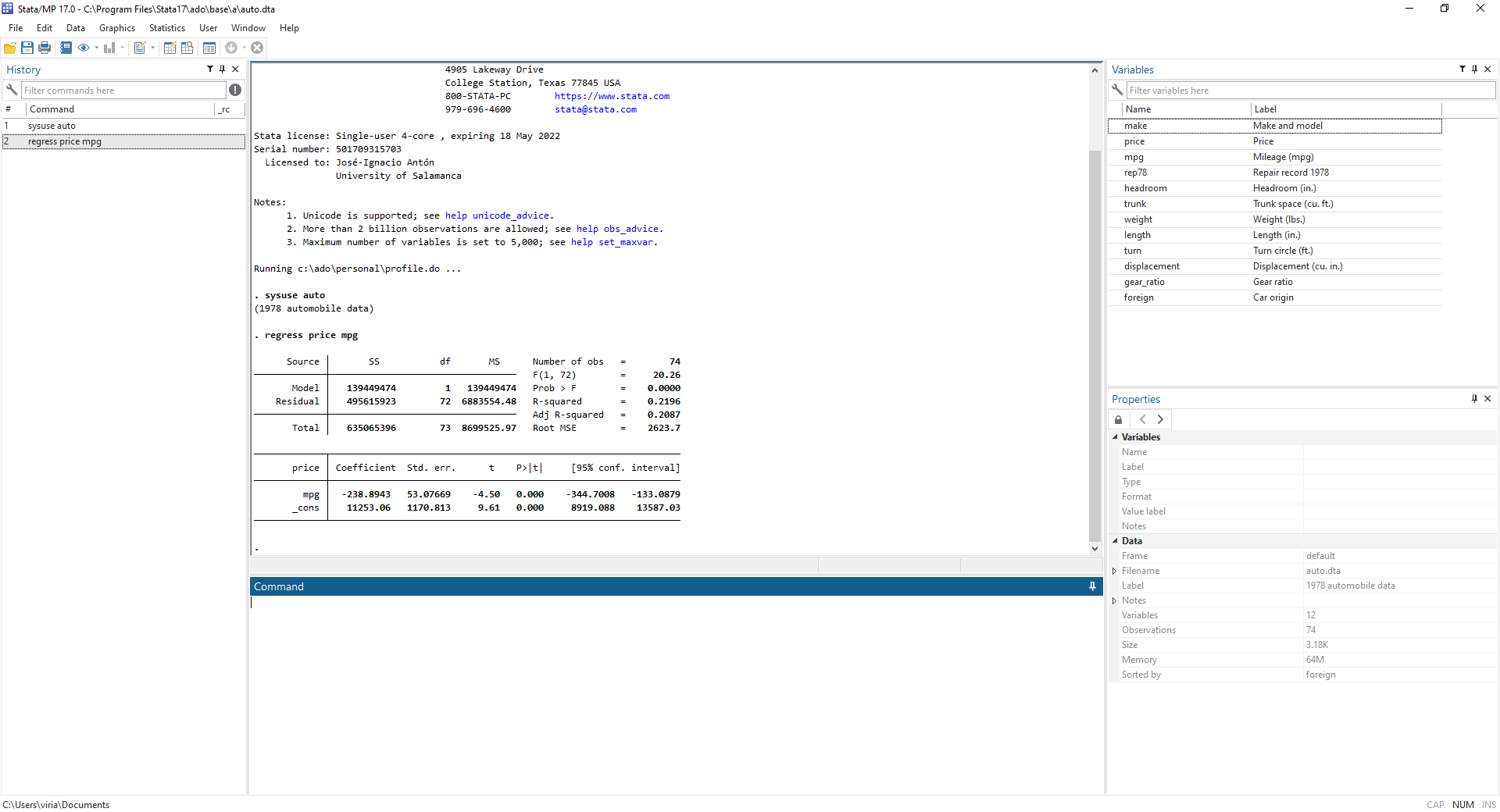
Conviene operar, preferentemente, con el editor de archivos
.do.

La ayuda de Stata es bastante buena y, además, nos
permite acceder directamente a los manuales en formato .pdf
del programa, que contienen breves explicaciones estadísticas, ejemplos
e incluso referencias. Es muy sencillo acudir a la ayuda.
help [command_or_topic_name] [, nonew name(viewername) marker(markername)]
De forma más genérica, podemos emplear
search word [word ...] [, search_options]
En segundo término, las cheatsheets
de Stata son un magnífico recurso a considerar.
En tercer lugar, tenemos un sinnúmero de manuales, más o menos especializados. Existen algunos especialmente recomendables, como el de J. Scott Long:

En el área de Economía, por ejemplo, tenemos una fantástica cantidad de recursos especializados

Algunas opciones de manuales introductorios son Acock (2018) y Kohler & Kreuter (2012). En español, hay bastantes menos recursos, entre los que destaca Escobar et al. (2012).
El tercer tipo de recursos son los tutoriales online. Hay tres de especial interés:
Además, los diferentes tipos de cursos que ofrece StataCorp son una opción
interesante, en particular, los NetCourses. Posiblemente, en
estos días, podemos encontrar muchos MOOCs interesantes con
Stata.
En la actualidad, una buena parte de los recursos de ayuda se ha
quedado obsoleto por la aparición de la inteligencia artificial. ChatGPT o Gemini pueden programar en
Stata (aunque no tan bien como en Python o
R) y podemos preguntarles dudas de todo tipo e incluso
pedirnos que nos realice los análisis tras proporcionarle los datos.
StataStataCada vez es más habitual que muchas instituciones y organismos
proporcionen la información en el formato nativo de Stata,
los archivos .dta, pero, con todo, no es lo habitual. En
muchas ocasiones nos encontramos formatos como .csv,
.txt, .raw, etc. Por ello, es necesario saber
cómo leer diferentes tipos de archivos en Stata.
Antes de nada, vamos a crear un nuevo archivo .do donde
iremos escribiendo la sintaxis y que podemos llamar
curso1.do. Es extremadamente importante y útil documentar
los archivos .do. En este sentido, el libro de Long (2009) o la guía de
Asjad
Naqvi ofrece excelentes consejos para sistematizar el trabajo.
Algunos comandos de utilidad son los siguientes:
.do
empleando * o // (el último, también en la
misma línea).Stata a no tener en cuenta
los saltos de línea empleando /// al final de la
línea.Stata omitir la lectura de todo el
contenido incluido entre /* y */.En primer lugar, podemos liberar el especio de trabajo con la instrucción
. clear all
Si queremos incluir comentarios podríamos escribir
. clear all // Liberar el espacio de trabajo . . // Liberar el espacio de trabajo . . clear all . . * Liberar el espacio de trabajo . . clear all
En segundo lugar, habitualmente, indicamos cuál es el directorio de trabajo.
cd ["]directory_name["]
En mi caso,
. cd "D:\Dropbox\curso_stata\sesión1" D:\Dropbox\curso_stata\sesión1 . pwd D:\Dropbox\curso_stata\sesión1
Vamos a utilizar los datos de la Encuesta de Condiciones de Vida que lleva a cabo el Instituto Nacional de Estadística. La base de datos y la documentación de la encuesta puede encontrarse aquí.
Los archivos se encuentran en formato .csv. Son archivos
de texto delimitados por un separador, en este caso, una coma (“,”).
Vamos a comenzar por un archivo de personas con algunas características
básicas (esudb18r.csv).
import delimited [using] filename [, import_delimited_options]
En mi caso,
. import delimited using "esudb18r.csv", clear delimiter(",")
(encoding automatically selected: ISO-8859-1)
(37 vars, 33,734 obs)
Existen otros muchos formatos, y podemos conocer cómo acceder a ellos
simplemente a través de la ayuda help import.
Podemos explorar la base de datos importada con el comando
browse.
. browse
Veremos que algunas variables se encuentran en formato numérico y otras, como cadenas de caracteres, pese a ser números.
Podemos solventar eso con el comando destring que
convierte todas las variables en formato texto a formato numérico sin
perder información (si hay pérdida de información, no lo hace). Existe,
asimismo, un comando para realizar la operación contraria
(help tostring).
destring [varlist] , {generate(newvarlist)|replace} [destring_options]
En nuestro caso, aplicamos el comando como sigue
destring _all, replacePodemos guardarlo mediante la instrucción save:
save [filename] [, save_options]
En mi caso, procedería como sigue para crear mi primer archivo
.dta.
. save "ecv18r.dta", replace file ecv18r.dta saved
Para abrir un archivo .dta, la instrucción es muy
sencilla.
use filename [, clear nolabel]
En mi caso,
. use "ecv18r.dta", clear
Por último, vamos a crear archivos logs. Son apropiados para documentar de manera muy informal los resultados (e.g., para enviarlos a un co-autor o echar un primer vistazo a los análisis estadísticos). Al comienzo de la parte que queremos “grabar”, añadimos
log using filename [, append replace [text|smcl] name(logname) nomsg]
Al final de la parte que deseamos reportar, empleamos
log close [logname | _all]
En nuestro caso, podríamos añadir al principio
capture log close // Para cerrar logs abiertos
log using curso1, replaceAl final,
log closePodemos abrir el archivo y observar que es similar a un archivo de texto enriquecido.
Tenemos varios comandos que nos permiten hacernos una idea de cuál es
el contenido de la base de datos, como describe,
codebook, browse, list,
tabulate, summarize o correlate,
entre otros. Además, podemos emplearlos en todo momento con
condicionales (if) o limitándonos a ciertas observaciones
(in). Para aplicarlos, conviene conocer antes cuáles son
los operadores. En este ámbito, el comando sort, que
permite ordenar la base de datos en función de una o varias variables,
resulta también muy utilizado.
| Operadores aritméticos | Operadores lógicos | Operadores relacionales (variables numéricas y alfanuméricas) |
|---|---|---|
| + suma | & y | > mayor que |
| - resta | | o | < menor que |
| * producto | ! no | >= mayor o igual |
| / cociente | ~ no | <= menor o igual |
| ^ potencia | == igual | |
| - negación | != distinto de | |
| + concatenación de texto | ~= distinto de |
Estos comandos se escriben como se expresa a continuación:
Descripción de los datos en la memoria
describe [varlist] [, memory_options]
Descripción del contenido de los datos
codebook [varlist] [if] [in] [, options]
Explorar los datos en la memoria
browse [varlist] [if] [in] [, nolabel]
Mostrar valores de las variables
list [varlist] [if] [in] [, options]
Estadísticos descriptivos
summarize [varlist] [if] [in] [weight] [, options]
Correlación entre variables
correlate [varlist] [if] [in] [weight] [, correlate_options]
Ordenar la base de datos por una o varias variables
sort varlist [in] [, stable]
Así, por ejemplo, podemos explorar la variable que recoge la
situación laboral de los españoles (rb210).
. codebook rb210
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
rb210 RB210
───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────
Type: Numeric (byte)
Range: [1,4] Units: 1
Unique values: 4 Missing .: 1/33,734
Tabulation: Freq. Value
13,021 1
2,990 2
6,183 3
11,539 4
1 .
Fácilmente, podemos ver la distribución de la misma.
. tabulate rb210
RB210 │ Freq. Percent Cum.
────────────┼───────────────────────────────────
1 │ 13,021 38.60 38.60
2 │ 2,990 8.86 47.46
3 │ 6,183 18.33 65.79
4 │ 11,539 34.21 100.00
────────────┼───────────────────────────────────
Total │ 33,733 100.00
Además, podemos ver dicha distribución para un grupo concreto. Por
ejemplo, estudiar cuál es la situación laboral de las mujeres (la
variable sexo es rb090).
. tabulate rb210 if rb090 == 2
RB210 │ Freq. Percent Cum.
────────────┼───────────────────────────────────
1 │ 6,023 34.48 34.48
2 │ 1,550 8.87 43.35
3 │ 2,562 14.67 58.02
4 │ 7,333 41.98 100.00
────────────┼───────────────────────────────────
Total │ 17,468 100.00
Un comando para inspeccionar directamente los datos es
list. Por ejemplo, podemos inspeccionar los 10 primeros
valores de la variable sexo (rb090):
. list rb090 in 1/10
┌───────┐
│ rb090 │
├───────┤
1. │ 1 │
2. │ 2 │
3. │ 2 │
4. │ 2 │
5. │ 2 │
├───────┤
6. │ 2 │
7. │ 2 │
8. │ 1 │
9. │ 2 │
10. │ 2 │
└───────┘
Para eliminar variables y observaciones de la base de datos podemos
emplear tanto drop como keep.
drop varlist drop if exp drop in range [if exp] keep varlist keep if exp keep in range [if exp]
Así, por ejemplo, podemos eliminar el mes de nacimiento de la persona
. drop rb070
O quedarnos únicamente con las mujeres
. keep if rb090 == 2 (16,266 observations deleted)
Volvemos a la base de datos original.
. use "ecv18r.dta", clear
Obviamente, resulta muy tedioso operar con estos nombres, por lo que lo habitual es etiquetar las variables y sus valores. También es posible etiquetar la base de datos.
Para etiquetar la base de datos empleamos
label data ["label"]
Por ejemplo, podemos llamar a nuestra base de datos “ECV-Datos básicos de la persona”:
. label data "ECV-Datos básicos de la persona"
El etiquetado de variables se realiza a través de la instrucción
label variable varname ["label"]
En nuestro caso, por ejemplo,
. label var rb090 "Sexo"
El etiqueda de las variables requiere, primero, definir una etiqueta para los valores y, posteriormente, asignarla a una variable. Así,
Definición de etiqueta
label define lblname # "label" [# "label" ...] [, add modify replace nofix]
Asignación de etiqueta
label values varlist lblname [, nofix]
En nuestro caso, por ejemplo,
. label define sexo_lab 1 "Hombre" 2 "Mujer" . label values rb090 sexo_lab
Además, existen algunas otras instrucciones para, por ejemplo, eliminar etiquetas o comprobar qué etiquetas se han definido.
En primer lugar, podemos cambiar el nombre de las variables con la
instrucción rename.
rename old_varname new_varname
En nuestro caso,
. rename rb090 sexo
Para estas tareas empleamos los comandos generate y
replace. El segundo de ellos es para variables ya
existentes.
generate [type] newvar[:lblname] =exp [if] [in] [, before(varname) | after(varname)] replace oldvar =exp [if] [in] [, nopromote]
A partir del año de nacimiento, rb080, vamos a generar
una nueva variable que recoja la edad.
. generate edad = 2018 - rb080
.
. // Etiquetamos la variable
.
. label var edad "Edad"
.
. // Observamos los estadísticos descriptivos de la nueva variable
.
. summarize edad
Variable │ Obs Mean Std. dev. Min Max
─────────────┼─────────────────────────────────────────────────────────
edad │ 33,734 44.8642 23.21889 0 86
Podemos generar una variable que recoja los grupos de edades:
. generate gedad = 1 if edad <= 29
(24,224 missing values generated)
. replace gedad = 2 if edad >= 30 & edad <= 49
(8,779 real changes made)
. replace gedad = 3 if edad >= 50 & edad <= 64
(7,886 real changes made)
. replace gedad = 4 if edad >= 65
(7,559 real changes made)
.
. // Etiqueamos la variable y sus valores
.
. label var gedad "Grupo de edad"
. label define gedad_lab 1 "Menor que 30 años" 2 "De 30 a 49 años" 3 "De 50 a 64 años" 4 "65 y más años"
. label values gedad gedad_lab
.
. tabulate gedad
Grupo de edad │ Freq. Percent Cum.
──────────────────┼───────────────────────────────────
Menor que 30 años │ 9,510 28.19 28.19
De 30 a 49 años │ 8,779 26.02 54.22
De 50 a 64 años │ 7,886 23.38 77.59
65 y más años │ 7,559 22.41 100.00
──────────────────┼───────────────────────────────────
Total │ 33,734 100.00
A través del comando recode podemos recodificar
variables.
| Regla | Ejemplo | Significado |
|---|---|---|
| # = # | 3 = 1 | 3 recodificado a 1 |
| # # = # | 2 . = 9 | 2 y . recodificados a 9 |
| #/# = # | 1/5 = 4 | 1 a 5 recodificados a 4 |
| nonmissing = # | nonmissing = 8 | Valores distintos de . recodificados a 8 |
| missing = # | missing = 9 | Valores . recodificados a 9 |
En términos generales,
recode varlist (rule) [(rule) ...] [, generate(newvar)]
En nuestro caso, podemos recodificar la variable gedad
en un menor número de categorías.
. recode gedad (1 2 = 1) (3 4 = 2)
(24,224 changes made to gedad)
.
. // Etiquetamos la nueva variable y sus valores
.
. label drop gedad_lab
. label define gedad_lab 1 "Menor de 50 años" 2 "50 y más años"
. label values gedad gedad_lab
.
. tabulate gedad
Grupo de edad │ Freq. Percent Cum.
─────────────────┼───────────────────────────────────
Menor de 50 años │ 18,289 54.22 54.22
50 y más años │ 15,445 45.78 100.00
─────────────────┼───────────────────────────────────
Total │ 33,734 100.00
El comando egen nos permite realizar muchas operaciones
a partir de una o varias variables (conteo, medias, etc.)
egen [type] newvar = fcn(arguments) [if] [in] [, options]
Por ejemplo, podemos calcular la edad promedio y almacenarla como una nueva variable.
. egen edadm = mean(edad)
Una particularidad de los microdatos es la existencia frecuente de
valores perdidos, debido a no respuesta, error de codificación o,
simplemente, no disponibilidad de la variable para ciertas personas
(e.g., salario para una persona que no está ocupada). Stata
tiene dos formas de codificar estos valores. La primera de ellas son
valores perdidos genéricos (.). La segunda consiste en
valores perdidos específicos, que se etiquetan con letras
(.a<.b<…<.z).
Matemáticamente, Stata considera los valores perdidos como
valores más elevados que el resto, es decir,
\[ . < .a < .b < \dots < .z \]
En ocasiones, nosotros mismos tenemos que manejar los problemas
asociados a los valores perdidos. Para ello, vamos recurrir a otro
archivo de la ECV 2018, el fichero detallado de información sobre los
individuos (esudb18p.csv) y procedemos de la misma forma
que más arriba.
import delimited using "esudb18p.csv", clear delimiter(",")
destring _all, replaceNos fijamos en la variable p78a_u, que, de acuerdo con
la documentación, recoge información sobre la ayuda que recibe el adulto
entrevistado si afronta limitaciones en su vida diaria.

Podemos ver que, en puridad, los valores -2 y -1 son valores perdidos. Se refieren a que la pregunta no es aplicable (porque el entrevistado no tenía limitaciones) o bien no contestó. Si queremos saber el tipo ayuda que recibe una persona con limitaciones diarias, los porcentajes ofrecidos por la tabulación de esta variable no son muy útiles.
. browse p78a_u
. tabulate p78a_u
P78a_U │ Freq. Percent Cum.
────────────┼───────────────────────────────────
-2 │ 22,051 78.31 78.31
-1 │ 2 0.01 78.31
1 │ 1,388 4.93 83.24
2 │ 2,248 7.98 91.23
3 │ 1,968 6.99 98.21
4 │ 44 0.16 98.37
5 │ 252 0.89 99.26
6 │ 176 0.62 99.89
7 │ 3 0.01 99.90
8 │ 25 0.09 99.99
9 │ 3 0.01 100.00
────────────┼───────────────────────────────────
Total │ 28,160 100.00
Una buena opción es, antes de nada, recodificar estos valores como perdidos, por ejemplo,
. recode p78a_u (-2 -1 = .) (22,053 changes made to p78a_u)
Otra opción posible podía haber sido codificar -2 como
.a y -1 como .b.
En algunos casos, esto puede ser mucho más relevante y no corregirlo es problemático. Por ejemplo, algunas bases de datos emplean valores extremos o sin sentido para los casos de no respuesta (e.g., -2, -999, 999999, etc.) en variables numéricas. En estos casos, conviene, antes de nada, recodificar estos valores como perdidos, por ejemplo, pueden codificar la no respuesta en la variable renta con el valor -9999. Si calculamos, por ejemplo, una media sin corregir esto, el valor numérico obtenido es completamente erróneo.
Una de las ventajas fundamentales del uso de Stata,
quizás solo compartida (y superada) por el programa R, es
la gran comunidad de usuarios con los que cuenta. Esto se plasma en
varias herramientas:
Los paquetes creados por los usuarios. Existen una
gran cantidad de paquetes que han sido creados por los usuarios de
Stata. Normalmente, están adecuadamente documentados. En
términos generales, podemos buscar paquetes de Stata con la
siguiente instrucción:
net search word [word ...] [, options]
Si sabemos el nombre del paquete, podemos emplearse
ssc install pkgname [, all replace]
Así, por ejemplo, podemos buscar paquetes que permitan realizar mediciones de pobreza con la siguiente instrucción
. net search poverty
(contacting http://www.stata.com)
53 packages found (Stata Journal listed first)
──────────────────────────────────────────────
st0723 from http://www.stata-journal.com/software/sj23-3
SJ23-3 st0723. Toolbox to estimate and analyze ... / Toolbox to estimate
and analyze multidimensional / poverty indices / by Nicolai Suppa, /
Support: nsuppa@ced.uab.es / After installation, type help {cmd:mptib}, /
{cmd:mpitb_assoc}, {cmd:mpitb_ctyselect}, / {cmd:mpitb_estcot},
st0492 from http://www.stata-journal.com/software/sj17-3
SJ17-3 st0492. Estimate the entire parametric class of Alkire-Foster
multidimensional poverty measures / Estimate the entire parametric class
of Alkire- / Foster multidimensional poverty measures / by Daniele
Pacifico, OECD, Paris, France / Felix Poege, Max Planck Institute for /
st0424 from http://www.stata-journal.com/software/sj16-1
SJ16-1 st0424. Difference-in-differences estimation /
Difference-in-differences estimation / by Juan M. villa, Brooks World
Poverty / Institute, University of Manchester, / Manchester, UK / Support:
juan.villalora@manchester.ac.uk / After installation, type help diff
sg117 from http://www.stata.com/stb/stb51
STB-51 sg115. Robust std errs for Foster-Greer-Thorbecke poverty ind. /
STB insert by / Dean Jolliffe, Center for Economic Research and Graduate
Education, / Czech Republic; / Anastassia Semykina, Center for Economic
Research and Graduate Education, / Czech Republic. / Support:
sg108 from http://www.stata.com/stb/stb48
STB-48 sg108. Computing poverty indices. / STB insert by Philippe Van
Kerm, GREBE, University of Namur, Belgium. / Support:
philippe.vankerm@fundp.ac.be / After installation, see help poverty.
shapley from https://staskolenikov.net/stata
shapley -- module to perform Shapley decomposition / Author: Stas
Kolenikov, skolenik@yahoo.com / This program performs, in some rather
general form, Shapley value / decomposition. The goal is to analyze
indices that do not possess / natural decomposition properties. The early
shapley from http://staskolenikov.net/stata
shapley -- module to perform Shapley decomposition / Author: Stas
Kolenikov, skolenik@yahoo.com / This program performs, in some rather
general form, Shapley value / decomposition. The goal is to analyze
indices that do not possess / natural decomposition properties. The early
adecomp from http://fmwww.bc.edu/RePEc/bocode/a
'ADECOMP': module to estimate Shapley Decomposition by Components of a
Welfare Measure / adecomp implements the Shapley decomposition of changes
in a / welfare indicator as proposed by Azevedo, Sanfelice and Nguyen /
(2012). Following Barros et al. (2006), this method takes / advantage of
apoverty from http://fmwww.bc.edu/RePEc/bocode/a
'APOVERTY': module to compute poverty measures / apoverty computes a
series of poverty measures based on the / (income) distribution described
by varname. It is a revised and / upgraded version of poverty published by
Philippe Van Kerm. / KW: poverty / KW: headcount / KW: Sen index / KW:
bcstats from http://fmwww.bc.edu/RePEc/bocode/b
'BCSTATS': module to analyze back check (field audit) data and compare it
to the original survey data / bcstats compares back check (i.e., field
audit, reinterview) / data and original survey data, producing a data set
of / comparisons. It completes enumerator checks for type 1 and type / 2
bmp2dta from http://fmwww.bc.edu/RePEc/bocode/b
'BMP2DTA': module to convert bitmap files to Stata datasets / Since the
advent of satellite imagery, researchers have turned / images into data
and processed it. This program makes the first / step easier in Stata, by
turning a Windows 24-bit bitmap file / into a Stata dataset with variables
cfby from http://fmwww.bc.edu/RePEc/bocode/c
'CFBY': module to compare datasets and produce discrepancy rates / cfby
compares the variables in varlist from the dataset in / memory to the
variables in varlist from the using dataset and / displays the discrepancy
rates by a common variable. It is / useful if you are doing data entry
cfout from http://fmwww.bc.edu/RePEc/bocode/c
'CFOUT': module to compare two datasets, saving a list of differences /
cfout compares the dataset in memory (the master dataset) to a / using
dataset. It uses unique ID variables to match observations. / cfout
optionally saves the list of differences to file. / KW: data management /
changemean from http://fmwww.bc.edu/RePEc/bocode/c
'CHANGEMEAN': module to compute Income and Inequality Contribution on
Poverty Variation / changemean decompose the poverty gap among two or more
subgroups / by income and inequality. / KW: poverty gap / KW: inequality
/ KW: income distribution / Requires: Stata version 8.0 /
diff from http://fmwww.bc.edu/RePEc/bocode/d
'DIFF': module to perform Differences in Differences estimation / diff
performs several differences in differences (diff-in-diff) / estimations
of the treatment effect of a given outcome variable / from a pooled base
line and follow up dataset: Single / Diff-in-Diff, Diff-in-Diff
drdecomp from http://fmwww.bc.edu/RePEc/bocode/d
'DRDECOMP': module to estimate Shapley value of growth and distribution
components of changes in poverty indicators / drdecomp implements the
shapley value of the Datt and Ravallion / (1992) decomposition of changes
in a welfare indicator into / growth and distribution, however, following
dstat from http://fmwww.bc.edu/RePEc/bocode/d
'DSTAT': module to compute summary statistics and distribution functions
including standard errors and optional covariate balancing / dstat unites
a variety of methods to describe (univariate) / statistical distributions.
Covered are density estimation, / histograms, cumulative distribution
egen_inequal from http://fmwww.bc.edu/RePEc/bocode/e
'EGEN_INEQUAL': module providing extensions to generate inequality and
poverty measures / The set of programs in this package uses egen to create
newvar of / the optionally specified storage type equal to one of the /
standard inequality and Foster-Greer-Thorbecke (FGT) poverty / measures.
fgt_ci from http://fmwww.bc.edu/RePEc/bocode/f
'FGT_CI': module to calculate and decompose Foster–Greer–Thorbecke
(and standard) concentration indices / This command combines two of the
most widely used measures in / the inequality and poverty literatures: the
concentration / index (CI) and the Foster–Greer–Thorbecke (FGT)
fpro from http://fmwww.bc.edu/RePEc/bocode/f
'FPRO': module to compute Financial Protection Indicators for Health
Expenditures / The package contains two commands (fpcata and fpimpov) to /
compute indicators of financial protection for health / expenditures.
fpcata computes the incidence of 'catastrophic' / health spending (the %
getcensus from http://fmwww.bc.edu/RePEc/bocode/g
'GETCENSUS': module to load American Community Survey data from the U.S.
Census Bureau API into Stata / getcensus is a Stata package for loading
American Community / Survey (ACS) data from the U.S. Census Bureau API
into Stata. It / also allows users to search the API data dictionaries for
glcurve from http://fmwww.bc.edu/RePEc/bocode/g
'GLCURVE': module to derive generalised Lorenz curve ordinates / Given
variable varname, call it x with c.d.f. F(x), glcurve / either draws its
Generalised Lorenz curve or generates two new / variables containing the
Generalised Lorenz ordinates for x, i.e. / GL(p) at each p = F(x) (or
glcurve5 from http://fmwww.bc.edu/RePEc/bocode/g
'GLCURVE5': module to derive generalised Lorenz curve ordinates with unit
record data (Stata 5 or 6) / Given a variable varname, call it x with
c.d.f. F(x), glcurve7 / draws its Generalised Lorenz curve and/or
generates two new / variables containing the Generalised Lorenz ordinates
glcurve7 from http://fmwww.bc.edu/RePEc/bocode/g
'GLCURVE7': module to derive generalised Lorenz curve ordinates with unit
record data (version 7) / Given a variable varname, call it x with c.d.f.
F(x), glcurve7 / draws its Generalised Lorenz curve and/or generates two
new / variables containing the Generalised Lorenz ordinates for x, i.e. /
hoishapely from http://fmwww.bc.edu/RePEc/bocode/h
'HOISHAPELY': module to perform Shapley Decomposition of the Human
Opportunity Index / hoishapley computes the Shapley decomposition of the
Human / Opportunity Index (HOI), it includes the estimation of the basic /
statistics like Coverage of Basic Opportunities (C), the / Dissimilarity
hoishapley from http://fmwww.bc.edu/RePEc/bocode/h
'HOISHAPLEY': module to perform Shapley Decomposition of the Human
Opportunity Index / hoishapley computes the Shapley decomposition of the
Human / Opportunity Index (HOI), it includes the estimation of the basic /
statistics like Coverage of Basic Opportunities (C), the / Dissimilarity
ipabcstats from http://fmwww.bc.edu/RePEc/bocode/i
'IPABCSTATS': module to compare survey and back check data, producing an
Excel output of comparisons and error rates / ipabcstats compares back
check data and survey data, producing / a data set of comparisons. It
completes enumerator checks for / type 1 and type 2 variables and
isopoverty from http://fmwww.bc.edu/RePEc/bocode/i
'ISOPOVERTY': module to generate data for Inequality-Poverty and
Iso-Poverty curves / isopoverty generates data that can be used to plot
the / Inequality-Poverty, Growth-Poverty and the Iso-Poverty curves. /
stepgrw or stepinq have to be stated otherwise the programme does / not
kanom from http://fmwww.bc.edu/RePEc/bocode/k
'KANOM': module to estimate Krippendorff's alpha for nominal variables /
kanom computes points estimates and 95 percent confidence / intervals for
Krippendorff's reliability coefficient alpha, for / nominal variables and
two measurements. It also tests the null / hypotheses that alpha is not
mergeall from http://fmwww.bc.edu/RePEc/bocode/m
'MERGEALL': module to merge multiple files / mergeall merges all of the
files in a folder without loss of / data due to variable storage types or
duplicate unique / identifiers. / KW: data management / KW: merge /
Requires: Stata version 10.1 / Distribution-Date: 20110708 / Author: Ryan
mpi from http://fmwww.bc.edu/RePEc/bocode/m
'MPI': module to compute the Alkire-Foster multidimensional poverty
measures and their decomposition by deprivation indicators and population
sub-groups / MPI estimates the Adjusted Multidimensional Headcount Ratio /
developed by Alkire and Foster (2011), also known as the /
mpitb from http://fmwww.bc.edu/RePEc/bocode/m
'MPITB': module to estimate and analyze multidimensional poverty indices
(MPI) / mpitb is a toolbox that offers several commands to facilitate /
specification, estimation, and analysis of multidimensional / poverty
indices (MPI) and supports the popular Alkire-Foster (AF) / framework to
mpovline from http://fmwww.bc.edu/RePEc/bocode/m
'MPOVLINE': module to calculate FGT0, FGT1 and FGT2 by intervals of
multiple thresholds / mpovline calculates FGT0, FGT1 and FGT2 by intervals
of multiple / lines. This ado can be used to calculate headcount for the
poor, / vulnerable and middle class lines as proposed by Ferreira et al /
orth_out from http://fmwww.bc.edu/RePEc/bocode/o
'ORTH_OUT': module to automate and export summary stats/orthogonality
tables / orth_out produces summary stats tables and orthogonality tables.
/ orth_out is useful in testing balance of means across variables / in
multiple groups, particularly the balance of baseline / characteristics
outdetect from http://fmwww.bc.edu/RePEc/bocode/o
'OUTDETECT': module to perform Outlier Detection for Inequality and
Poverty Analysis / outdetect identifies outliers (extreme values) in the /
distribution of a variable, and assesses their impact on a / selection of
popular inequality and poverty measures. The / procedure by which outliers
pip from http://fmwww.bc.edu/RePEc/bocode/p
'PIP': module to access poverty and inequality data from the World Bank's
Poverty and Inequality Platform (PIP) / The pip command allows Stata users
to compute poverty and / inequality indicators for more than 160 countries
and regions / included in the World Bank’s database of household
pobrezaecu from http://fmwww.bc.edu/RePEc/bocode/p
'POBREZAECU': module to predict poverty in Ecuador / pobrezaECU predicts
income poverty in Ecuador, a year ahead, / from the quarterly household
survey called ENEMDU. / KW: poverty / KW: Ecuador / KW: prediction /
Requires: Stata version 12 / Distribution-Date: 20180512 / Author: Daniel
povcalnet from http://fmwww.bc.edu/RePEc/bocode/p
'POVCALNET': module to access World Bank Global Poverty and Inequality
measures / The povcalnet commands allows Stata users to compute poverty /
and inequality indicators for more than 160 countries and / regions in the
World Bank's database of household surveys. It has / the same
povdeco from http://fmwww.bc.edu/RePEc/bocode/p
'POVDECO': module to calculate poverty indices with decomposition by
subgroup / povdeco estimates three poverty indices from the Foster, /
Greer and Thorbecke (1984) class, FGT(a), plus related / statistics (such
as mean income amongst the poor). FGT(0) is / the headcount ratio (the
poverty from http://fmwww.bc.edu/RePEc/bocode/p
'POVERTY': module to calculate poverty measures / poverty computes a
series of poverty measures based on the / (income) distribution described
by varname. The poverty measures / that can be computed by poverty are:
headcount ratio, / aggregate poverty gap, poverty gap ratio, income gap
povguide from http://fmwww.bc.edu/RePEc/bocode/p
'POVGUIDE': module to generate the U.S. Poverty Guideline value for a
given family size and year / This generates the official Poverty Guideline
value as / established by the United States Department of Health and Human
/ Services. This is one of two official poverty levels, the other / being
povguide2 from http://fmwww.bc.edu/RePEc/bocode/p
'POVGUIDE2': module to compute Federal Poverty Guidelines by family size
and year, 1973-2025 / This is an extension of the original Stata module
POVGUIDE by / David Kantor written to include guideline data from
1973-2025, / whereas the original module stopped at 2008. Moreover, I have
povimp from http://fmwww.bc.edu/RePEc/bocode/p
'POVIMP': module to provide poverty estimates in the absence of actual
consumption data / povimp provides poverty estimates in the absence of
actual / consumption data. / KW: poverty / KW: imputation / KW:
consumption / KW: inequality / Requires: Stata version 12 /
povtime from http://fmwww.bc.edu/RePEc/bocode/p
'POVTIME': module to compute aggregate intertemporal poverty measures
(poverty in a panel accounting for time) / povtime computes aggregate
intertemporal poverty measures / (poverty accounting for time) in a
balanced panel of individuals. / The program computes the family of
prosperity from http://fmwww.bc.edu/RePEc/bocode/p
'PROSPERITY': module to compute Shared Prosperity Convergence Index / The
command prosperity calculates the Shared Prosperity / Convergence Index
-SPCI-. This is the new indicator that the / World Bank uses to measure
the progress in the growth and / inequality reduction. The base indicator
quantiles from http://fmwww.bc.edu/RePEc/bocode/q
'QUANTILES': module to categorize by quantiles / quantiles creates a new
variable (newvar) that categorizes / varname by its quantiles. It differs
from xtile because the / categories are defined by the ideal size of the
quantile rather / than by the cutpoints, therefore yielding less unequaly
rddsga from http://fmwww.bc.edu/RePEc/bocode/r
'RDDSGA': module to conduct subgroup analysis for regression discontinuity
designs / rddsga allows to conduct a binary subgroup analysis in RDD /
settings based on inverse propensity score weights (IPSW). / Observations
in each subgroup are weighted by the inverse of / their conditional
readreplace from http://fmwww.bc.edu/RePEc/bocode/r
'READREPLACE': module to make replacements that are specified in an
external dataset / eadreplace modifies the dataset currently in memory by
making / replacements that are specified in an external dataset, the /
replacements file. / KW: data management / KW: data entry / KW: replace /
s2s from http://fmwww.bc.edu/RePEc/bocode/s
'S2S': module to provide survey to survey imputation tool / Obtaining
consistent estimates on poverty over time as well / as monitoring poverty
trends on a timely basis is essential for / poverty reduction. However,
these objectives are not readily / achieved in practice where household
tex3pt from http://fmwww.bc.edu/RePEc/bocode/t
'TEX3PT': module to produce LaTeX documents from estout with
threeparttable / tex3pt takes .tex output from esttab and writes it into a
LaTeX / file using threeparttable. This greatly improves the level of /
compatibility between LaTeX and esttab. Since this program uses / the
veracrypt from http://fmwww.bc.edu/RePEc/bocode/v
'VERACRYPT': module to mount or dismount a VeraCrypt volume / veracrypt
mounts or dismounts a VeraCrypt volume. / KW: veracrypt / KW: data
management / Requires: Stata version 9 / Distribution-Date: 20160926 /
Author: Patrick McNeal, Abdul Latif Jameel Poverty Action Lab, MIT /
st0543 from http://www.stata-journal.com/software/sj18-4
SJ18-4 st0543. Fit dynamic random-effects probit... / Fit dynamic
random-effects probit models with / unobserved heterogeneity / by Raffaele
Grotti, / Department of Political and Social Sciences / European
University Institute / San Domenico di Fiesole, Italy / Giorgio Cutuli,
xtpdyn from http://fmwww.bc.edu/RePEc/bocode/x
'XTPDYN': module to estimate dynamic random effects probit model with
unobserved heterogeneity / xtpdyn fits dynamic random-effects probit
models (meprobit and / xtprobit) with unobserved heterogeneity. It
implements Wooldridge / simple solution to the initial condition problem
12 references found in tables of contents
─────────────────────────────────────────
http://www.stata-journal.com/software/sj23-3/
Stata Journal volume 23, issue 3 / Update: iefieldkit: Commands for
primary / data collection and cleaning / Extract the travel distance and
travel time / between two locations from the Baidu Maps / API
(http://api.map.baidu.com) / Training text regression models in Stata /
http://www.stata-journal.com/software/sj17-3/
Stata Journal volume 17, issue 3 / Update: A set of utilities for managing
/ missing values / Update: Design plots for graphical summary / of a
response given factors / Update: One-, two-, and three-way bar charts /
for tables / Provide graph schemes sensitive to color / vision deficiency
http://www.stata.com/stb/stb51/
STB-51 September 1999 / Update to defv / Update to labedit / Update to
varxplor / Update of cut to Stata 6 / Calculating the product of
observations / Alternative ranking procedures / 3D surface plots / A
simple contour plot / Distribution function plots / Quantile plots,
http://www.stata.com/stb/stb48/
STB-48 March 1999 / Drawing Venn diagrams / Diagnostic plots for
Singh-Maddala and Dagum distrib / Analysis of income distributions /
Creation of bivariate random lognormal variables / Fitting Singh-Maddala
and Dagum distrib. by max. like. / Generalized Lorenz curves and related
http://fmwww.bc.edu/RePEc/bocode/a/
module to estimate models with two fixed effects / module to compute
unbiased IV regression / module for scatter plot with linear and/or
quadratic fit, automatically annotated / module to provide Gradient Solver
for Ahlfeldt & Barr (2022): The economics of skyscrapers / module to
http://fmwww.bc.edu/RePEc/bocode/c/
module to implement machine learning classification in Stata / module to
implement machine learning classification in Stata / module to cache all
other Stata commands / module to cache all other Stata commands / module
to generate calendar / module to estimate proportions and means after
http://fmwww.bc.edu/RePEc/bocode/d/
module to create network visualizations using D3.js to view in browser /
module to produce terrible dad jokes / module to provide utilities for
directed acyclic graphs / module to fit a Generalized Beta (Type 2)
distribution to grouped data via ML / module to fit a Dagum distribution
http://fmwww.bc.edu/RePEc/bocode/e/
module to estimate endogenous attribute attendance models / module to
compute Extended Sample Autocorrelation Function / module to perform
extreme bound analysis / module to perform Entropy reweighting to create
balanced samples / module to perform entropy balancing / module to perform
http://fmwww.bc.edu/RePEc/bocode/i/
module to import International Aid Transparency Initiative data / module
to compute measures of interaction contrast (biological interaction) /
module to compute Interaction Effects in Linear and Generalized Linear
Models / module to compute Intraclass correlation coefficients based on
http://fmwww.bc.edu/RePEc/bocode/m/
module to implement interpoint distance distribution analysis / module to
unabbreviate Global Macro Lists / module to compute the macroF evaluation
criterion for multi-class outcomes / module to perform Dickey-Fuller test
on panel data / module to create dot plot for summarizing pooled estimates
http://fmwww.bc.edu/RePEc/bocode/o/
module to compute the Blinder-Oaxaca decomposition / module to compute
decompositions of outcome differentials / module to compute the
Blinder-Oaxaca decomposition / module to identify differences in values
across observations for a variable / module to display observations of
http://fmwww.bc.edu/RePEc/bocode/p/
module to calculate confidence limits of a regression coefficient from the
p-value / module to convert between minutes per mile and miles per hour /
module to perform Page's L trend test for ordered alternatives / module to
create paired datasets from individual-per-row data / module for plots of
. ssc install povdeco
checking povdeco consistency and verifying not already installed...
all files already exist and are up to date.
Además, es frecuente que otros autores ofrezcan sus programas con más o menos sofisticación y mejor o peor presentación.
Stata
Journal. Se trata de una revista de StataCorp, indexada en
el Journal Citation Reports, donde se publican estrategias de uso de
Stata y se proponen nuevos comandos y se ponen a
disposición de los usuarios. El artículo
de Jann (2008)
representa un ejemplo típico: introduce el paquete oaxaca,
proporcionando unas nociones estadísticas mínimas y explicando el
funcionamiento del mismo, ilustrado con ejemplos.

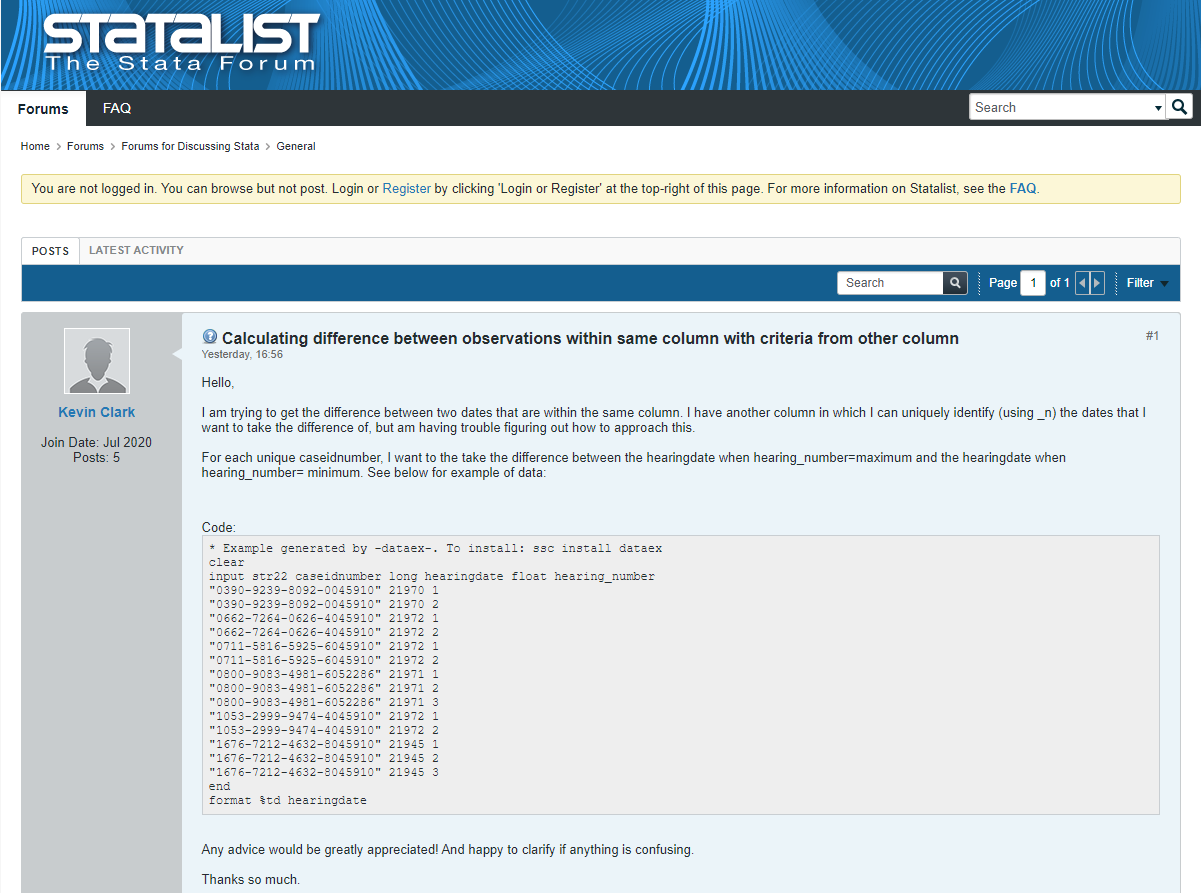
Statalist. Inicialmente, fue una lista de correo. En la actualidad, se trata de un foro de usuarios orientado, fundamentalmente, a resolver dudas. Antes de preguntar es importante asegurarse de que el tema no ha sido discutido con anterioridad y, en nuestra duda, incluir un minimum working example en el que se acote el problema.