Inicio Sesión 1 Sesión 2 Sesión 3 Sesión 4 Sesión 5 Ejercicios
Stata presenta buenas capacidades gráficas y estas han
ido mejorando a lo largo del tiempo de forma muy sustancial. En Escobar et al. (2012)
se realiza una aproximación al tema y tres referencias muy recomendables
son Cox (2014) y
Mitchell (2012),
sobre la realización de gráficos con este paquete estadístico, y Schwabish (2014), que
proporciona unos consejos generales sobre cómo realizar buenos
gráficos.
En primer lugar, resulta muy sencillo realizar gráficos con
Stata. Al mismo tiempo, elaborar figuras totalmente
satisfactorias suele requerir bastante tiempo \(\rightarrow\) resulta esencial que
nuestros gráficos sean reproducibles.
Así, por ejemplo, no es complicado realizar gráficos muy sofisticados
con la interfaz de Stata. Su sistema de ventanas es muy
intuitivo y nos permite controlar múltiples opciones.
El problema radica en la reproducibilidad: si
reiniciamos el análisis gráfico o salimos del programa, tendremos que
acordarnos de todas las opciones seleccionadas y, además, tendremos que
repetir los cambios realizados en el editor de gráficos sobre la propia
figura. \(\rightarrow\) Opción
práctica: realizamos el gráfico con los menús de ventanas,
empleando submit para ver cada cambio realizado y, cuando
estemos satisfechos, copiamos el código y podemos reutilizarlo con
adaptaciones.
Un avance sustancial viene dado por el paquete grstyle,
que debe utilizarse conjuntamente palettes y
colrspace (Jann, 2018a, 2018b). También es
muy potente el paquete brewscheme. La idea de estos
paquetes es que podemos definir previamente el formato de los gráficos
(colores, ancho de las líneas, etc.) y, posteriormente, emplear comandos
sencillos para la realización de los gráficos donde no tengamos que
especificar muchas opciones. Podemos instalar estos paquetes con las
siguientes instrucciones:
ssc install grstyle, replace
ssc install palettes, replace
ssc install colrspace, replace
ssc install brewscheme, replaceEstos paquetes nos facilitan bastante el trabajo, pero es muy posible que queramos, en cada gráfico, añadir opciones específicas de personalización más allá de los parámetros generales.
Stata cuenta con un formato nativo .gph con
bastante calidad y que puede ser una buena opción para guardar las
figuras elaboradas con la posibilidad de modificarlas luego. Además,
naturalmente, podemos copiar las figuras producidas en la ventana de
gráficos y pegarlas en un documento de un procesador de textos (e.g.,
Microsoft Word) o un programa de edición de imágenes (e.g., Microsoft
Paint). Sin embargo, existe un gran número de formatos en los que
Stata puede guardar los graficos: .ps,
.eps, .svg, .wmf,
.emf, .pdf, .png,
.tif, .gif y .jpg. Formatos como
.wmf y .emf son muy apropiados para
aplicaciones de Microsoft Office (e.g., Microsoft Word). Sin embargo,
los formatos de vectores asegura muchísima calidad y son los empleados
en edición profesional (.ps, .eps,
.svg, .pdf, .png). La instrucción
para exportar gráficos es la siguiente:
graph export newfilename.suffix [, options]
StataEn primer lugar, vamos a configurar el formato de los gráficos para
que nos sirva para todas las figuras que elaboraremos con el comando
grstyle. Sin embargo, como se mencionaba anteriormente, de
forma habitual, necesitaremos implementar opciones adicionales. En esta
sección, vamos a tratar de elaborar gráficos de alta calidad aptos para
publicaciones científicas siguiendo los formatos sugeridos por Schwabish (2014) para
Ciencias Sociales. Dado que el número de gráficos que Stata
puede realizar no puede ser abarcado (siquiera lejanamente) en un curso
de estas características, aquí nos limitamos a presentar una serie de
figuras que ilustran su potencial. En particular, elaboramos en
Stata todas las figuras que presenta Schwabish (2014). El
proceso de realización de los mismos se fundamenta en procesos de
ensayo-error y en emplear las herramientas de ayuda destacadas con
anterioridad. Hemos creado las figuras a través del sistema de ventanas
y hemos exportado la sintaxis obtenida con la instrucción
submit. El proceso de realización de los mismos se
fundamenta en procesos de ensayo-error y en emplear las herramientas de
ayuda destacadas con anterioridad.
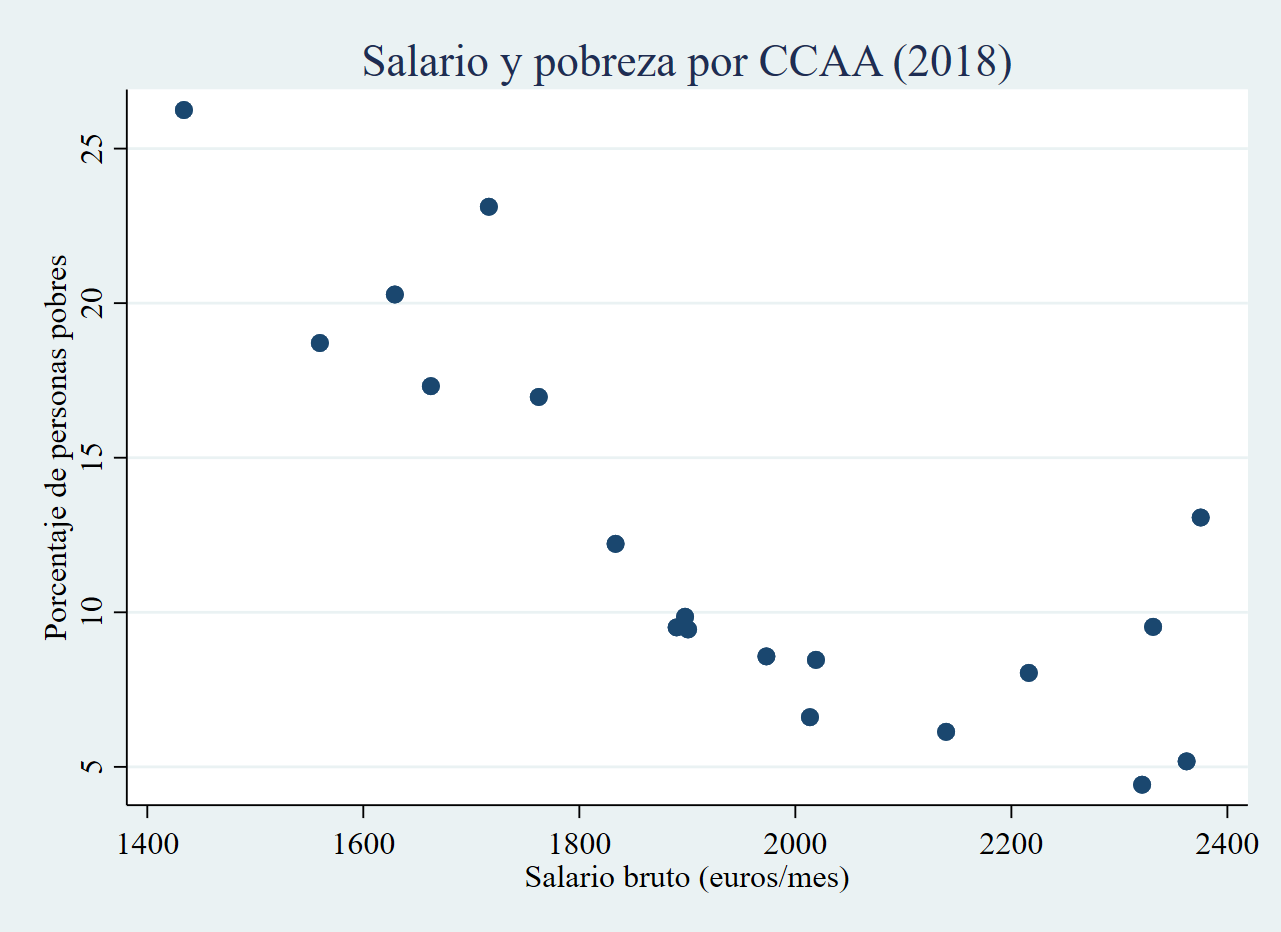
Comenzamos por un gráfico sencillo, en el que tratamos de ver la
relación el salario medio de una Comunidad Autónoma y la proporción de
personas pobres (tasa de pobreza). Realizaremos en primer lugar el
gráfico sin personalización alguna y, posteriormente, elaboraremos una
figura con opciones personalizadas. El proceso es eminentemente
learning by doing y la forma habitual de
trabajo es elaborar el gráfico con los menús y obtener el código que
responde a nuestras preferencias, que llevaremos al archivo
.do para poder reproducir el gráfico cuando lo deseemos o
reutilizarlo con otras bases de datos.
. // Fijamos el directorio de trabajo
.
. cd "D:\Dropbox\curso_stata\sesión4"
D:\Dropbox\curso_stata\sesión4
.
. // Abrimos el archivo
.
. use "ecv18.dta", clear
(ECV 2018)
.
. // Calculamos el salario medio y la tasa de pobreza por CCAA
.
. generate rentaasa = rentamonasag + rentanomonasag
(5,362 missing values generated)
. generate nmesesasa = nmesesasatc + 0.5*nmesesasatp
(5,578 missing values generated)
. keep if rentaasa > 0 & rentaasa < .
(19,369 observations deleted)
. keep if nmesesasa > 0 & nmesesasa < .
(2,585 observations deleted)
.
. generate salario = rentaasa/nmesesasa
. label variable salario "Salario bruto (euros/mes)"
.
. // Creamos la base de datos con los estadísticos de interés
.
. collapse (mean) salario hpobreza (count) nper = pid [pweight=peso], by(region)
.
. // Expresamos la variable pobreza en tanto por 100
.
. replace hpobreza = 100*hpobreza
(19 real changes made)
.
. // El patrón por defecto de Stata
.
. twoway (scatter hpobreza salario), ///
> xtitle("Salario bruto (euros/mes)") ytitle("Porcentaje de personas pobres") ///
> title("Salario y pobreza por CCAA (2018)")
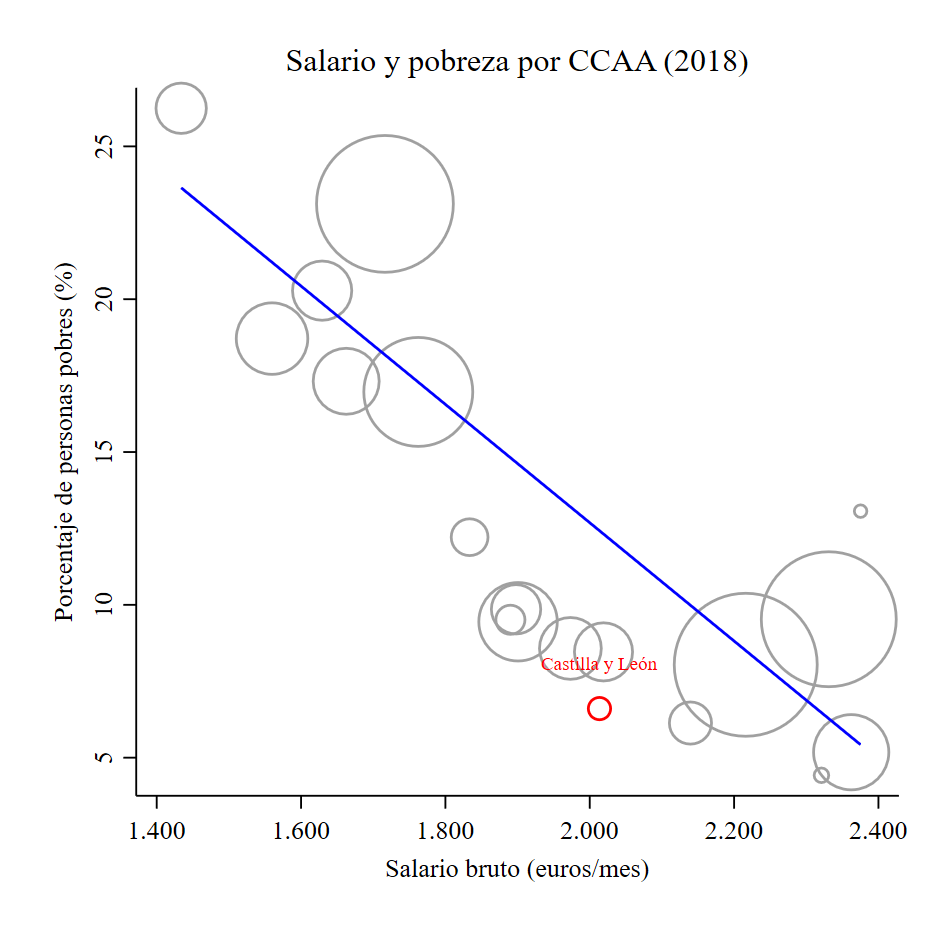
Ahora vamos a realizar el mismo gráfico de una manera mucho más personalizada.
. // Podemos cambiar el tipo de letra
.
. graph set window fontface "Times New Roman"
. graph set window fontfacemono "Times New Roman"
. graph set window fontfacesans "Times New Roman"
. graph set window fontfaceserif "Times New Roman"
. graph set window fontfacesymbol "Symbol"
.
. // Comenzamos fijando un tipo de gráfico como base o eliminar todo esa base
.
. grstyle clear
. grstyle init
. grstyle set plain
.
. // Fijamos un fondo blanco
.
. grstyle color background white
.
. // Definimos las dimensiones del gráfico
.
. grstyle graphsize x 4
. grstyle graphsize y 4
.
. // Podemos eliminar las líneas auxiliares
.
. grstyle set nogrid
.
. // Seleccionamos una paleta de colores (e.g., paleta hue)
.
. grstyle set color hue, n(4)
.
. // Eliminamos la línea que rodea a la leyenda
.
. grstyle linestyle legend none
.
. // Ponemos la leyenda arriba
.
. grstyle set legend 6
.
. // Formato de los marcadores
.
. grstyle symbol p circle_hollow
.
. // Color de los marcadores
.
. grstyle color p1markline gs10
.
. grstyle color p1markfill gs10
.
. // Color de las series
.
. grstyle set color red green orange blue
.
. // Gráfico de ejemplo
.
. twoway (scatter hpobreza salario [pweight = nper] if region != 9) ///
> (scatter hpobreza salario [pweight = nper] if region == 9, mcolor(red)) ///
> (scatter hpobreza salario [pweight = nper] if region == 9, mlabel(region) mlabsize(vsmall) mlabcolor(red) mlabposition(12) mlabgap(medsmall) mcolor(none)) ///
> (lfit hpobreza salario [pweight = nper]), ///
> title("Salario y pobreza por CCAA (2018)", size(medsmall) margin(small)) ///
> xtitle("Salario bruto (euros/mes)", margin(small) size(small)) xlabel(, format(%9,0gc) labsize(small)) ///
> ytitle("Porcentaje de personas pobres (%)", margin(small) size(small)) ylabel(, format(%2,0fc) labsize(small)) ///
> legend(off)
En este ejemplo, vamos a representar el salario por grupos de edad y nivel de estudios.
. // Abrimos el archivo
.
. use "ecv18.dta", clear
(ECV 2018)
.
. // Calculamos la edad y los grupos de edad
.
. generate edad = 2018 - anonac
. generate edadg = 1 if edad > 16 & edad <= 29
(29,586 missing values generated)
. replace edadg = 2 if edad >= 30 & edad <= 44
(6,145 real changes made)
. replace edadg = 3 if edad >= 45 & edad <= 54
(5,361 real changes made)
. replace edadg = 4 if edad >= 55 & edad <= 64
(5,159 real changes made)
. label variable edadg "Grupos de edad"
. label define edadg_lab 1 "16-29" 2 "30-44" 3 "45-54" 4 "55-64"
. label values edadg edadg_lab
.
. // Calculamos grupos de niveles educativos
.
. generate educg = 1 if educ == 0 | educ == 100
(27,003 missing values generated)
. replace educg = 2 if educ == 200 | educ == 344 | educ == 353
(8,725 real changes made)
. replace educg = 3 if educ == 300 | educ == 354 | educ == 400 | educ == 450
(4,735 real changes made)
. replace educg = 4 if educ == 500
(7,969 real changes made)
.
. label variable educg "Educación (agrupada)"
. label define educg_lab 1 "Elemental" 2 "Básica" 3 "Media" 4 "Superior"
. label values educg educg_lab
.
. // Calculamos el salario
.
. generate rentaasa = rentamonasag + rentanomonasag
(5,362 missing values generated)
. generate nmesesasa = nmesesasatc + 0.5*nmesesasatp
(5,578 missing values generated)
. keep if rentaasa > 0 & rentaasa < .
(19,369 observations deleted)
. keep if nmesesasa > 0 & nmesesasa < .
(2,585 observations deleted)
.
. generate salario = rentaasa/nmesesasa
. label variable salario "Salario bruto (euros/mes)"
.
. // Eliminamos valores perdidos
.
. drop if educg == . | edadg == . | salario == .
(177 observations deleted)
.
. // Creamos la base de datos con los estadísticos de interés
.
. collapse (mean) salario [pweight=peso], by(edadg educg)
.
. // Realizamos algunas manipulaciones para representar los datos
.
. expand 5
(64 observations created)
.
. bysort edadg educg: generate copy = _n
. label variable copy "Copy for graph"
. label define copy_lab 1 "Elemental" 2 "Básica" 3 "Media" 4 "Superior"
. label values copy copy_lab
.
. forvalues i = 1(1)4 {
2. drop if educg == `i' & copy == `i'
3.
. }
(4 observations deleted)
(4 observations deleted)
(4 observations deleted)
(4 observations deleted)
.
. bysort edadg educg: egen meducg =mean(educg)
.
. replace educg = 5 if copy == 5
(16 real changes made)
.
. replace copy = meducg if copy == 5
(16 real changes made)
.
. // Realizamos el gráfico de interés
.
. twoway ///
> (line salario edadg if educg == 1, lcolor(gs10)) ///
> (line salario edadg if educg == 2, lcolor(gs10)) ///
> (line salario edadg if educg == 3, lcolor(gs10)) ///
> (line salario edadg if educg == 4, lcolor(gs10)) ///
> (line salario edadg if educg == 5, lcolor(blue)), ///
> ytitle("Salario mensual", size(small) margin(small)) ylabel(, labsize(small) format(%5,0fc)) ///
> xtitle("Edad", size(small) margin(small)) xlabel(1 "16-29" 2 "30-44" 3 "45-54" 4 "55-64", labsize(small)) ///
> by(copy, note("") legend(off) imargin(medsmall) title("Salario por edad y nivel educativo (2018)", size(medsmall) margin(small))) ///
> subtitle(, size(small)) ///
> xsize(4) ysize(4)
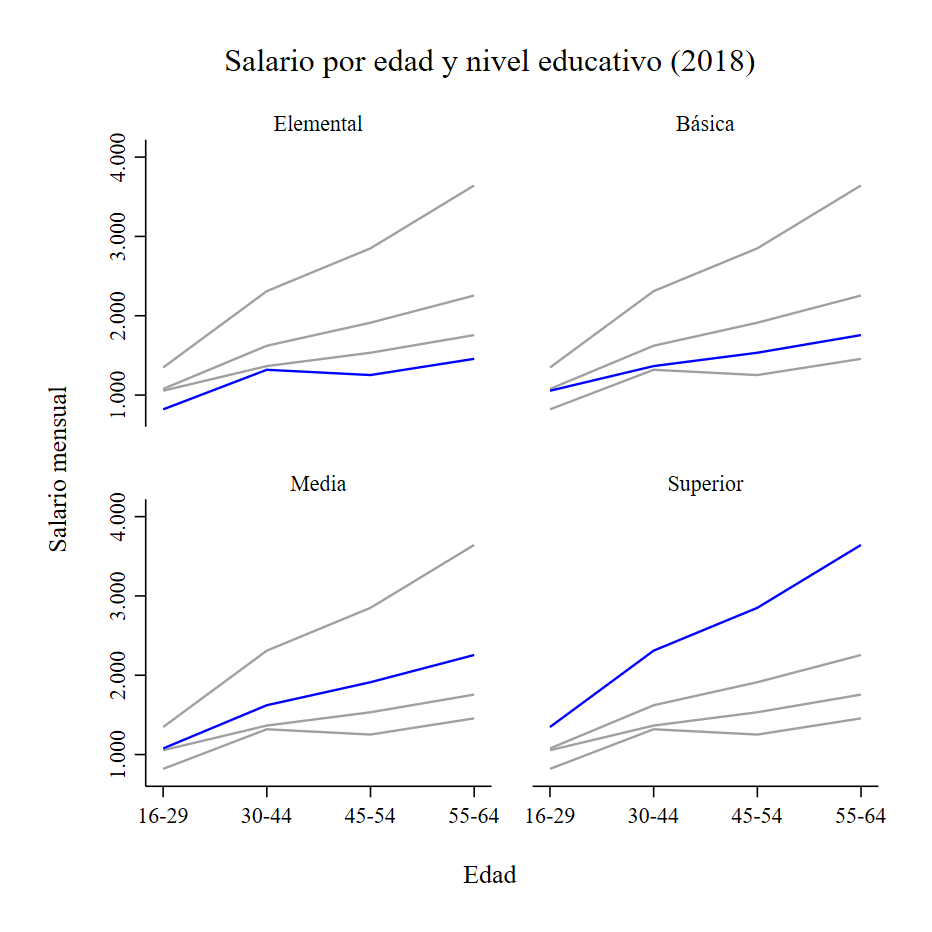
En este subapartado, elaboramos una figura que muestra la tasa de empleo por sexo y nivel educativo en España.
. // Abrimos el archivo
.
. use "ecv18.dta", clear
(ECV 2018)
.
. // Calculamos la edad
.
. generate edad = 2018 - anonac
.
. // Calculamos la tasa de empleo
.
. gen empleo = 0 if edad >= 18 & edad <= 64
(13,265 missing values generated)
. recode empleo (0 = 1) if sitact == 1
(12,867 changes made to empleo)
.
. // Calculamos los grupos de niveles educativos
.
. generate educg = 1 if educ == 0 | educ == 100
(27,003 missing values generated)
. replace educg = 2 if educ == 200 | educ == 344 | educ == 353
(8,725 real changes made)
. replace educg = 3 if educ == 300 | educ == 354 | educ == 400 | educ == 450
(4,735 real changes made)
. replace educg = 4 if educ == 500
(7,969 real changes made)
.
. label variable educg "Educación (agrupada)"
. label define educg_lab 1 "Educación elemental" 2 "Educación básica" 3 "Educación media" 4 "Educación superior"
. label values educg educg_lab
.
. keep if empleo < . & educg < .
(13,442 observations deleted)
.
. // Creamos la base de datos con los estadísticos de interés
.
. collapse (mean) empleo [pweight=peso], by(sexo educg)
.
. // Expresamos la tasa de empleo en tanto por 100
.
. replace empleo = 100*empleo
(8 real changes made)
.
. // Elaboramos el gráfico de interés
.
. twoway ///
> (line educg empleo if educg == 1, lcolor(black)) ///
> (line educg empleo if educg == 2, lcolor(black)) ///
> (line educg empleo if educg == 3, lcolor(black)) ///
> (line educg empleo if educg == 4, lcolor(black)) ///
> (scatter educg empleo if sexo == 1, mcolor(navy) msize(4-pt) msymbol(circle) mlabcolor()) ///
> (scatter educg empleo if sexo == 2, mcolor(orange) msize(4-pt) msymbol(circle) mlabel(educg) mlabsize(small) mlabcolor(black) mlabposition(9) mlabgap(small)), ///
> title("Tasa de empleo por sexo y nivel educativo en España (2018)", size(medsmall) margin(small)) ///
> yscale(off) ylabel(0(1)4) ///
> xtitle("Porcentaje de personas empleadas (%)", margin(small) size(small)) xlabel(0(20)100, labsize(vsmall)) ///
> legend(on order(5 "Hombres" 6 "Mujeres") size(vsmall) color(black) nobox position(11))
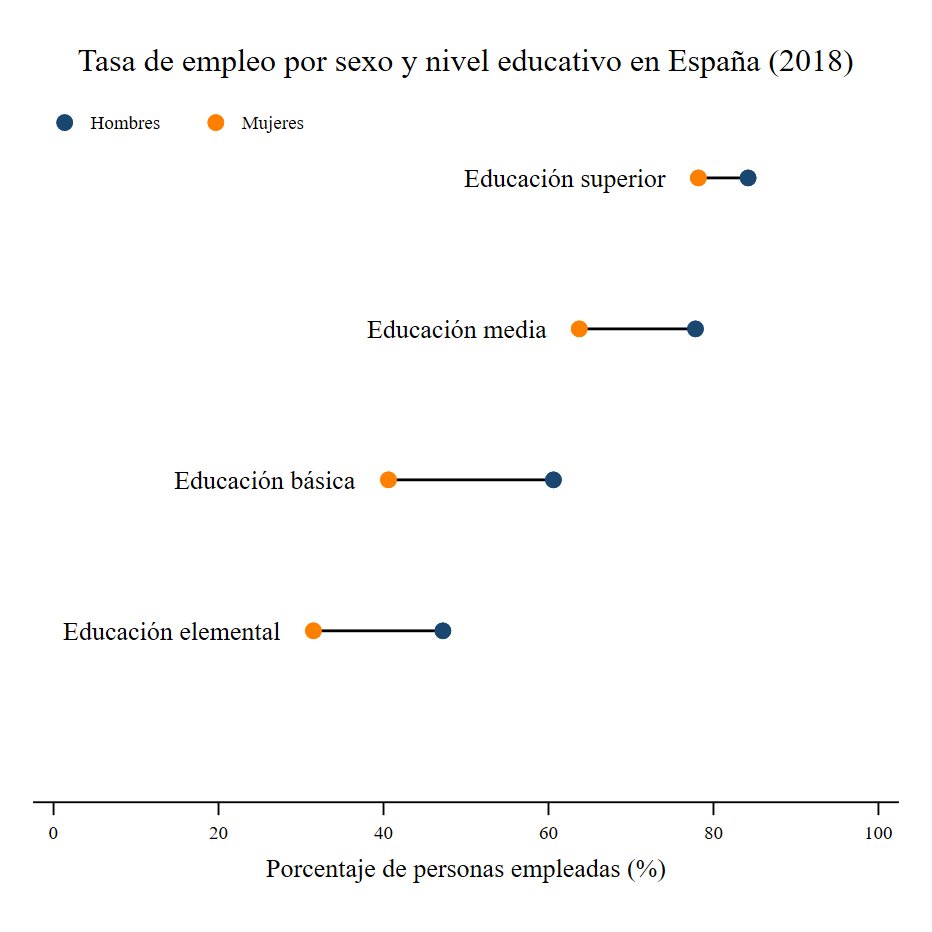
A continuación, mostramos la tasa de pobreza por nivel educativo y
sexo en España en el año 2018. Además, en este ejemplo, vamos a usar el
editor de gráficos de Stata.
. // Abrimos el archivo
.
. use "ecv18.dta", clear
(ECV 2018)
.
. // Calculamos los grupos de niveles educativos
.
. generate educg = 1 if educ == 0 | educ == 100
(27,003 missing values generated)
. replace educg = 2 if educ == 200 | educ == 344 | educ == 353
(8,725 real changes made)
. replace educg = 3 if educ == 300 | educ == 354 | educ == 400 | educ == 450
(4,735 real changes made)
. replace educg = 4 if educ == 500
(7,969 real changes made)
.
. label variable educg "Educación (agrupada)"
. label define educg_lab 1 "Educación elemental" 2 "Educación básica" 3 "Educación media" 4 "Educación superior"
. label values educg educg_lab
.
. keep if educg < .
(5,574 observations deleted)
.
. // Creamos la base de datos con los estadísticos de interés
.
. collapse (mean) hpobreza [pweight=peso], by(sexo educg)
.
. // Expresamos la tasa de pobreza en tanto por 100
.
. replace hpobreza = 100*hpobreza
(8 real changes made)
.
. // Reordenamos los datos para representarlos
.
. reshape wide hpobreza, i(educg) j(sexo)
(j = 1 2)
Data Long -> Wide
─────────────────────────────────────────────────────────────────────────────
Number of observations 8 -> 4
Number of variables 3 -> 3
j variable (2 values) sexo -> (dropped)
xij variables:
hpobreza -> hpobreza1 hpobreza2
─────────────────────────────────────────────────────────────────────────────
.
. // Elaboramos el gráfico de interés
.
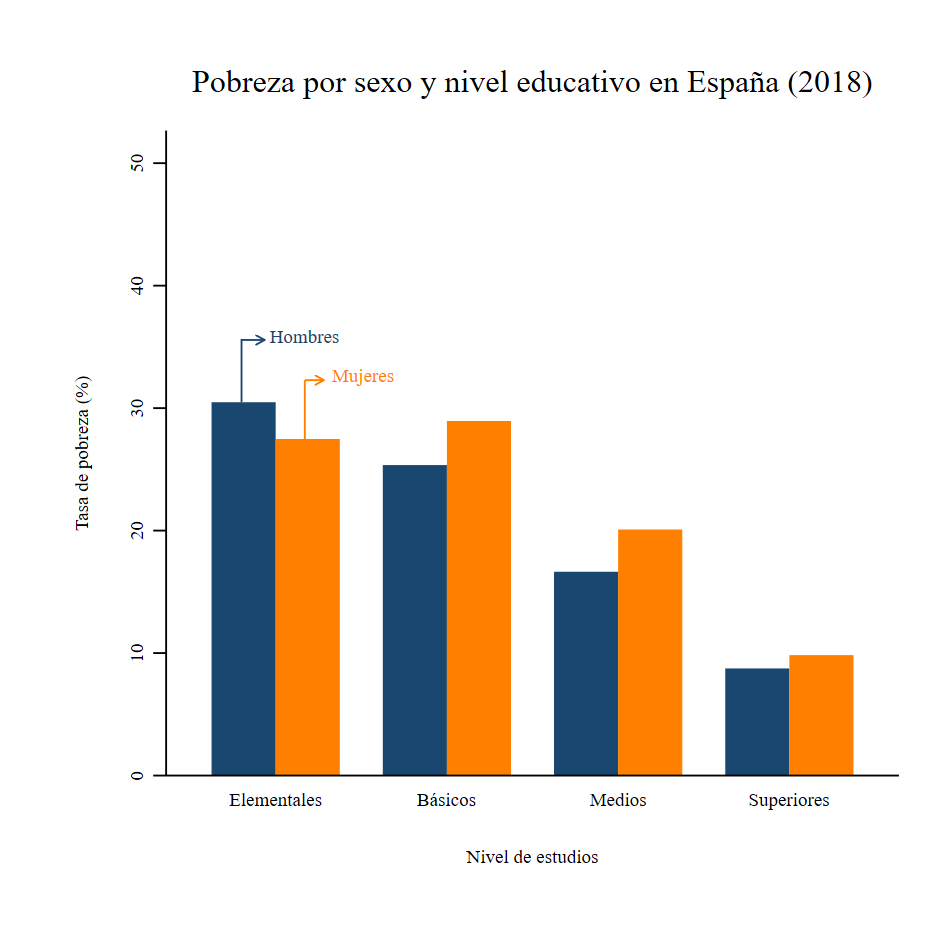
. graph bar (asis) hpobreza1 hpobreza2, ///
> over(educg, relabel(1 "Elementales" 2 "Básicos" 3 "Medios" 4 "Superiores") label(labsize(vsmall))) ///
> bar(1, fcolor(navy) lcolor(none)) ///
> bar(2, fcolor(orange) lcolor(none)) ///
> ytitle(Tasa de pobreza (%)) ytitle(, size(vsmall) margin(sides)) ylabel(0(10)50, labsize(vsmall) nogrid) ///
> title(Pobreza por sexo y nivel educativo en España (2018), size(medsmall) margin(top_bottom)) legend(off) ///
> b1title("Nivel de estudios", size(vsmall) margin(top_bottom))
.
. gr_edit plotregion1.AddTextBox added_text editor 35.8934560474294 10.62503501939819
. gr_edit plotregion1.added_text_new = 1
. gr_edit plotregion1.added_text_rec = 1
. gr_edit plotregion1.added_text[1].style.editstyle angle(default) size( sztype(points) val(2) allow_pct(1)) ///
> color(navy) horizontal(left) vertical(middle) margin( gleft( sztype(relative) val(0) allow_pct(1)) ///
> gright( sztype(relative) val(0) allow_pct(1)) gtop( sztype(relative) val(0) allow_pct(1)) ///
> gbottom( sztype(relative) val(0) allow_pct(1))) linegap( sztype(relative) val(0) allow_pct(1)) ///
> drawbox(no) boxmargin( gleft( sztype(relative) val(0) allow_pct(1)) ///
> gright( sztype(relative) val(0) allow_pct(1)) gtop( sztype(relative) val(0) allow_pct(1)) ///
> gbottom( sztype(relative) val(0) allow_pct(1))) fillcolor(bluishgray) ///
> linestyle( width( sztype(relative) val(.2) allow_pct(1)) color(black) pattern(solid) align(inside)) box_alignment(east) editcopy
. gr_edit plotregion1.added_text[1].style.editstyle size(vsmall) editcopy
. gr_edit plotregion1.added_text[1].text = {}
. gr_edit plotregion1.added_text[1].text.Arrpush Hombres
.
. gr_edit plotregion1.AddTextBox added_text editor 32.6954873184468 19.95200785068754
. gr_edit plotregion1.added_text_new = 2
. gr_edit plotregion1.added_text_rec = 2
. gr_edit plotregion1.added_text[2].style.editstyle angle(default) size( sztype(relative) val(4.1667) allow_pct(1)) ///
> color(navy) horizontal(left) vertical(middle) margin( gleft( sztype(relative) val(0) allow_pct(1)) ///
> gright( sztype(relative) val(0) allow_pct(1)) gtop( sztype(relative) val(0) allow_pct(1)) ///
> gbottom( sztype(relative) val(0) allow_pct(1))) ///
> linegap( sztype(relative) val(0) allow_pct(1)) drawbox(no) boxmargin( gleft( sztype(relative) val(0) allow_pct(1)) ///
> gright( sztype(relative) val(0) allow_pct(1)) gtop( sztype(relative) val(0) allow_pct(1)) ///
> gbottom( sztype(relative) val(0) allow_pct(1))) fillcolor(bluishgray) ///
> linestyle( width( sztype(relative) val(.2) allow_pct(1)) color(black) pattern(solid) align(inside)) box_alignment(east) editcopy
. gr_edit plotregion1.added_text[2].style.editstyle size(vsmall) editcopy
. gr_edit plotregion1.added_text[2].text = {}
. gr_edit plotregion1.added_text[2].text.Arrpush Mujeres
. gr_edit plotregion1.added_text[2].style.editstyle color(orange) editcopy
.
. gr_edit plotregion1.AddLine added_lines editor 6.412853740751393 30.4815089676127 6.412853740751393 35.64745845289226
. gr_edit plotregion1.added_lines_new = 1
. gr_edit plotregion1.added_lines_rec = 1
. gr_edit plotregion1.added_lines[1].style.editstyle linestyle( width( sztype(relative) val(.2) allow_pct(1)) ///
> color(navy) pattern(solid) align(inside)) headstyle( symbol(circle) linestyle( width( sztype(relative) val(.2) allow_pct(1)) ///
> color(navy) pattern(solid) align(inside)) fillcolor(navy) size( sztype(relative) val(1.04166) allow_pct(1)) ///
> angle(stdarrow) symangle(zero) backsymbol(none) backline( width( sztype(relative) val(.2) allow_pct(1)) ///
> color(navy) pattern(solid) align(inside)) backcolor(navy) backsize( sztype(relative) val(0) allow_pct(1)) ///
> backangle(stdarrow) backsymangle(zero)) headpos(neither) editcopy
.
. gr_edit plotregion1.AddLine added_lines editor 6.412853740751393 35.56545925471323 9.872859791068407 35.56545925471323
. gr_edit plotregion1.added_lines_new = 2
. gr_edit plotregion1.added_lines_rec = 2
. gr_edit plotregion1.added_lines[2].style.editstyle linestyle( width( sztype(relative) val(.2) allow_pct(1)) ///
> color(navy) pattern(solid) align(inside)) headstyle( symbol(circle) linestyle( width( sztype(relative) val(.2) allow_pct(1)) ///
> color(navy) pattern(solid) align(inside)) fillcolor(navy) size( sztype(relative) val(1.04166) allow_pct(1)) ///
> angle(stdarrow) symangle(zero) backsymbol(none) backline( width( sztype(relative) val(.2) allow_pct(1)) ///
> color(black) pattern(solid) align(inside)) backcolor(black) backsize( sztype(relative) val(0) allow_pct(1)) ///
> backangle(stdarrow) backsymangle(zero)) headpos(head) editcopy
.
. gr_edit plotregion1.AddLine added_lines editor 15.89026161770668 27.44753863498822 15.89026161770668 32.2854913275516
. gr_edit plotregion1.added_lines_new = 3
. gr_edit plotregion1.added_lines_rec = 3
. gr_edit plotregion1.added_lines[3].style.editstyle linestyle( width( sztype(relative) val(.2) allow_pct(1)) ///
> color(orange) pattern(solid) align(inside)) headstyle( symbol(circle) linestyle( width( sztype(relative) val(.2) allow_pct(1)) ///
> color(orange) pattern(solid) align(inside)) fillcolor(orange) size( sztype(relative) val(1.04166) allow_pct(1)) ///
> angle(stdarrow) symangle(zero) backsymbol(none) backline( width( sztype(relative) val(.2) allow_pct(1)) ///
> color(black) pattern(solid) align(inside)) backcolor(navy) backsize( sztype(relative) val(0) allow_pct(1)) ///
> backangle(stdarrow) backsymangle(zero)) headpos(neither) editcopy
.
. gr_edit plotregion1.AddLine added_lines editor 15.89026161770668 32.28549132755161 18.74852748535989 32.28549132755161
. gr_edit plotregion1.added_lines_new = 4
. gr_edit plotregion1.added_lines_rec = 4
. gr_edit plotregion1.added_lines[4].style.editstyle linestyle( width( sztype(relative) val(.2) allow_pct(1)) ///
> color(orange) pattern(solid) align(inside)) headstyle( symbol(circle) linestyle( width( sztype(relative) val(.2) allow_pct(1)) ///
> color(orange) pattern(solid) align(inside)) fillcolor(orange) size( sztype(relative) val(1.04166) allow_pct(1)) ///
> angle(stdarrow) symangle(zero) backsymbol(none) backline( width( sztype(relative) val(.2) allow_pct(1)) ///
> color(black) pattern(solid) align(inside)) backcolor(black) backsize( sztype(relative) val(0) allow_pct(1)) ///
> backangle(stdarrow) backsymangle(zero)) headpos(head) editcopy
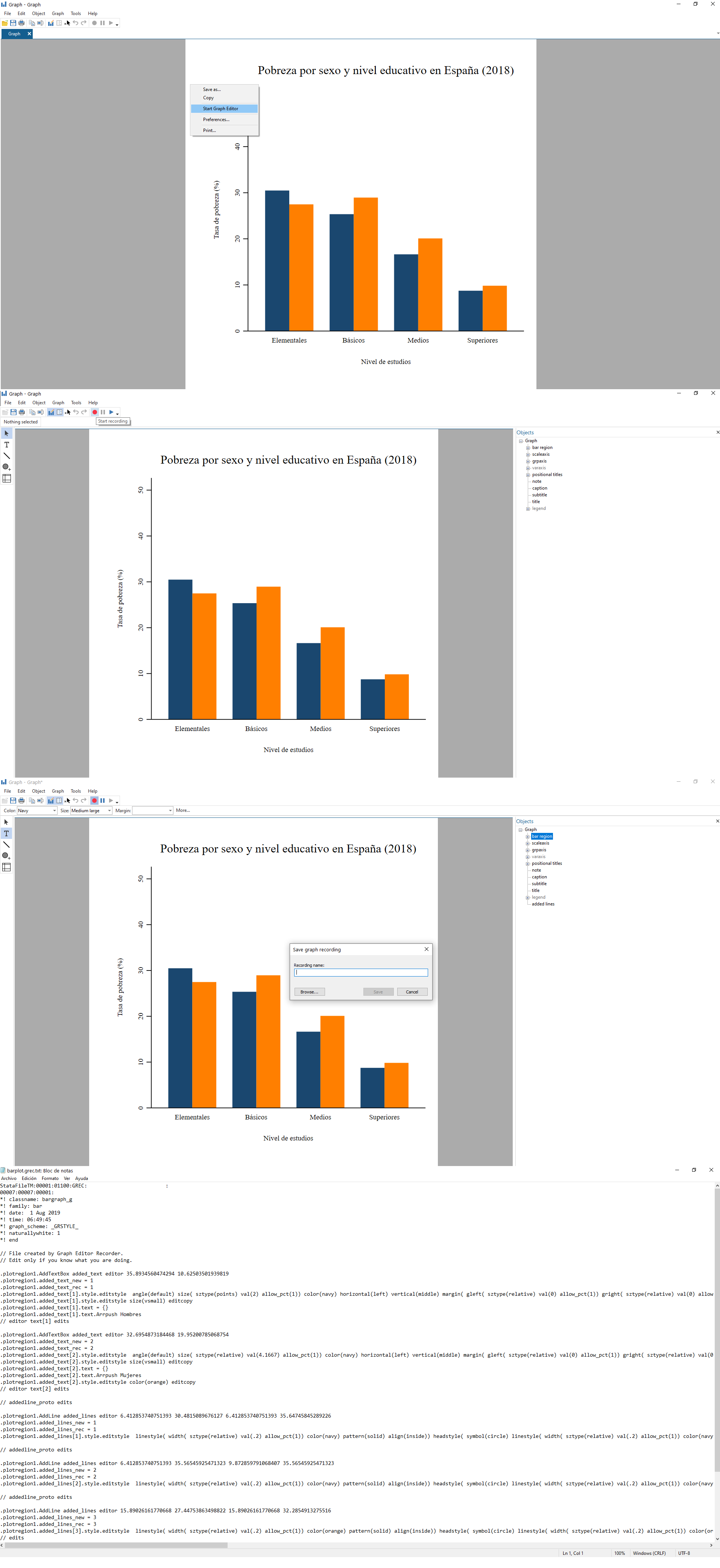
La última parte del código corresponde al editor de gráficos de
Stata, que permite hacer cambios manualmente. Si queremos
asegurar que el gráfico es reproducible podemos seguir estos pasos:
Paso 1. Abrimos el gráfico en el editor.
Paso 2. Pulsamos Start recording.
Paso 3. Realizamos los cambios que queramos (añadir cuadros de texto, flechas, etc.).
Paso 4. Finalizamos la grabación pulsando
End recording.
Paso 5. Abrimos el archivo .grec creado
en el blog de notas (o el propio editor de archivos .do de
Stata).
Paso 6. Copiamos el código y relevante al arhivo
.do tras el grafico, eliminamos el . e
incluimos antes de cada instrucción gr_edit seguido de un
espacio.
Se trata de uno de los fuertes de Stata, que es
complicado de abordar con otro tipo de programas (e.g., Microsoft
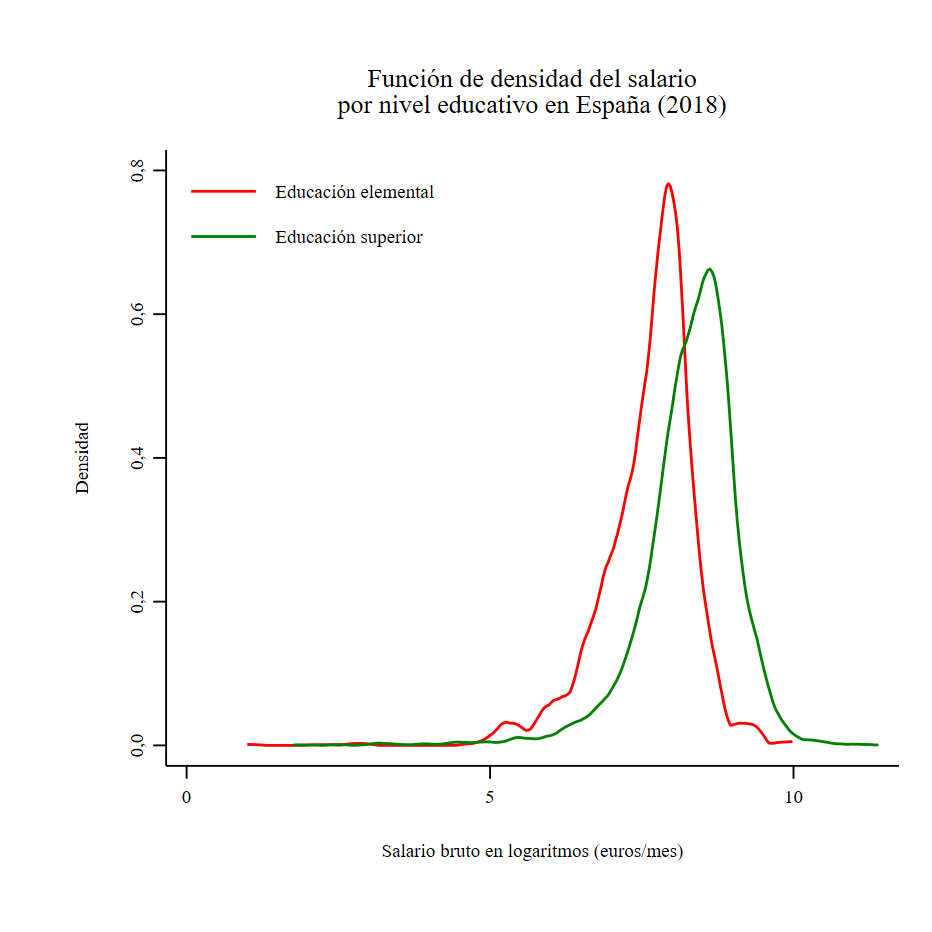
Excel). En este caso, vamos a representar las funciones de densidad del
salario mensual de las personas con educación elemental y educación
superior.
. // Abrimos el archivo
.
. use "ecv18.dta", clear
(ECV 2018)
.
. // Calculamos el salario
.
. generate rentaasa = rentamonasag + rentamonasag
(5,362 missing values generated)
. generate nmesesasa = nmesesasatc + 0.5*nmesesasatp
(5,578 missing values generated)
. keep if rentaasa > 0 & rentaasa < .
(19,416 observations deleted)
. keep if nmesesasa > 0 & nmesesasa < .
(2,540 observations deleted)
.
. generate salario = rentaasa/nmesesasa
. label variable salario "Salario bruto (euros/mes)"
.
. // Lo expresamos en logaritmos
.
. generate logsalario = ln(salario)
. label variable logsalario "Salario en logaritmos"
.
. // Calculamos los grupos de niveles educativos
.
. generate educg = 1 if educ == 0 | educ == 100
(10,934 missing values generated)
. replace educg = 2 if educ == 200 | educ == 344 | educ == 353
(3,331 real changes made)
. replace educg = 3 if educ == 300 | educ == 354 | educ == 400 | educ == 450
(2,509 real changes made)
. replace educg = 4 if educ == 500
(5,094 real changes made)
.
. label variable educg "Educación (agrupada)"
. label define educg_lab 1 "Educación elemental" 2 "Educación básica" 3 "Educación media" 4 "Educación superior"
. label values educg educg_lab
.
. keep if educg < .
(0 observations deleted)
.
. // Eliminamos valores perdidos
.
. keep if logsalario < . | educg < .
(0 observations deleted)
.
. // Elaboramos el gráfico de interés
.
. twoway ///
> (kdensity logsalario if educg == 1 [aweight = peso]) ///
> (kdensity logsalario [aweight = educg == 4]), ///
> ytitle("Densidad", size(vsmall) margin(sides)) ylabel(, labsize(vsmall) format(%02,1fc)) ///
> xtitle("Salario bruto en logaritmos (euros/mes)", size(vsmall) margin(top_bottom)) xlabel(, labsize(vsmall)) ///
> title("Función de densidad del salario" "por nivel educativo en España (2018)", size(small) margin(top_bottom)) ///
> legend(on order(1 "Educación elemental" 2 "Educación superior") cols(1) size(vsmall) position(10) ring(0))
No es, desde luego, el mejor software para esta tarea, pero, sin
embargo, existen algunos comandos que pueden ser muy útiles para
usuarios poco exigentes (e.g., investigadores en Ciencias Sociales para
los que los mapas no son centrales). Existen varios paquetes para esta
tarea, como spmap, geo2xy o
geoplot. En este curso, emplearemos el más moderno de
ellos: geoplot. La principal ventaja de
geoplot sobre otras soluciones previas es que permite
trabajar con más de una capa sin dificultad.
Podemos encontrar una buena introducción al uso de este paquete en esta presentación del autor, Ben Jann. Además, en su web, este autor nos ofrece algunos ejemplos de cursos que imparte. Una gran referencia, de carácter general, sobre elaboración de mapas en Stata es posiblemente la colección de guías y tutoriales de Asjad Naqvi. En particular, este académico ofrece un tutorial para `geoplot’.
Un rasgo distintivo de geoplot es su funcionamiento con
los llamados frames de Stata. Básicamente, se
trata de una capacidad de Stata para tener en la memoria
varias bases de datos al mismo tiempo (como, por ejemplo,
R), Asjad Naqvi ofrece en Medium una excelente introducción
a su uso.
geoplot requiere la instalación adicional de algunos
paquetes: de shp2dta y mif2dta. Así, podemos
instalar todos los parquetes necesarios de la siguiente forma:
net install geoplot, replace from(https://raw.githubusercontent.com/benjann/geoplot/main/)
ssc install spmap
ssc install shp2dta
ssc install mif2dta
ssc install palettes, replace
ssc install colrspace, replace
ssc install moremata, replace
ssc install geo2xy, replace
ssc install xls2dta, replaceCon geoplot, Stata puede manejar dos tipos
de formatos gráficos: ESRI shapefiles (incluye un
archivo .shp de coordenadas, un archivo .shx,
un índice, y un archivo .dbf, con códigos) y el
MapInfo Interchange Format files (que comprende un
archivo .mif con las coordenadas y un archivo
.mid con los códigos). El manejo del primer tipo de formato
es, con frecuencia, más sencillo. Para explorar las capacidades de
Stata en esta área, vamos a realizar un mapa de España por
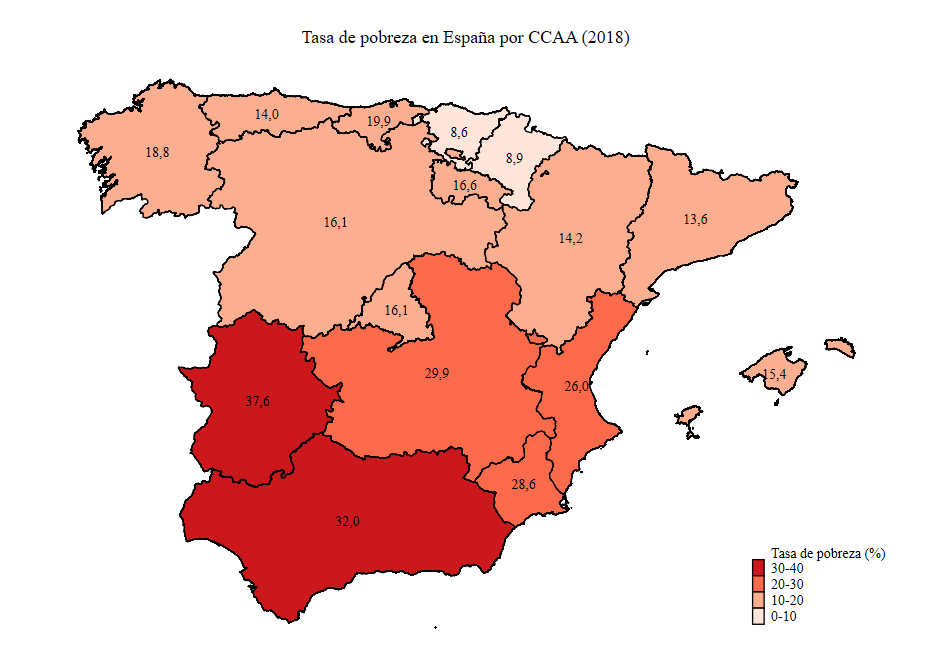
Comunidades Autónomas con su tasa de pobreza.
Procedemos en varios pasos.
Paso 1. Buscamos los ESRI
shapefiles que precisamos. En este caso, podemos encontrarlos
en muchos lugares. El mapa “oficial” se encuentra en el Centro
Nacional de Información Geográfica, los copiamos a la carpeta de
trabajo y descomprimimos la carpeta. Nuestro interés radica en la
carpeta
Recintos autonómicos: poligonos_autonomicas_inspire_peninbal_ etrs89.
Nos vamos a limitar a la península, por simplicidad. Extraemos sus
archivos y los situamos en la carpeta de trabajo.
Paso 2. Creamos los archivos de atributos y
coordenadas con la siguiente instrucción de geoplot:
. geoframe translate ccaa using "recintos_autonomicas_inspire_peninbal_etrs89", replace // Crea los archivos ccaa.dta (atributos) y ccaa_shp.dta (coordenadas) (importing shp file) (5 vars, 728,101 obs) (importing dbf file) (9 vars, 19 obs) (files ccaa.dta and ccaa_shp.dta saved) (type geoframe create ccaa to load the data)
El archivo de atributos ccaa.dta contiene las líneas que
definen las Comunidades Autónomas y se convertirá en nuestra primera
capa.
Paso 3. Creamos dos archivos destinados a crear dos capas adicionales: un cifras de pobreza para elaborar un mapa coroplético y un archivo con las mismas cifras que serán etiquetas
. // Abrimos el archivo . . use "ecv18.dta", clear (ECV 2018) . . // Calculamos los estadísticos de interés . . collapse (mean) hpobreza [pweight = peso], by(region) . . // Expresamos la tasa de pobreza en tanto por 100 . . replace hpobreza = 100*hpobreza (19 real changes made) . . // Eliminamos Canarias, Ceuta y Melilla . . drop if region == 19 (1 observation deleted) . . // Recodificamos las regiones para enlazar con la variable stid de ccaa_attr.dta . . recode region (1=11) (2=3) (3=5) (4=15) (5=14) (6=16) (7=2) (8=12) (9=6) (10=7) (11=10) (12=8) (13=9) (14=4) (15=1) (16=13) (17=17) (18=18) (16 changes made to region) . . // Eliminamos las etiquetas de los valores para evitar confusiones y le ponemos los valores nuevos . . label drop region_lab . . label define region_lab 1 "Andalucía" 2 "Aragón" 3 "Principado de Asturias" 4 "Illes Balears" 5 "Cantabria" 6 "Castilla y León" 7 "Castilla-La Mancha" 8 "Cataluña" 9 "Comunidad Valenciana" 10 "Extremadura" /// > 11 "Galicia" 12 "Comunidad de Madrid" 13 "Región de Murcia" 14 "Comunidad Foral de Navarra" 15 "País Vasco" 16 "La Rioja" 17 "Ceuta" 18 "Melilla" . label values region region_lab . . // Cambiamos el nombre de la variable de enlace . . rename region _ID . . // Guardamos el archivo que servirá para crear la segunda capa (destinada a las áreas del mapa coroplético de niveles de pobreza) . . save "ccaa_pobreza.dta", replace file ccaa_pobreza.dta saved . . // Abrimos el archivo de atributos y lo fusionamos con el archivo de datos de pobreza, de forma que tenemos una variable asociada a cada unidad . . use "ccaa.dta", clear . . merge 1:1 _ID using "ccaa_pobreza.dta", keep(match) nogenerate noreport . . save "ccaa_pobreza_datos.dta", replace file ccaa_pobreza_datos.dta saved . . // Creamos el archivo destinado a las etiquetas por el mismo procedimiento . . use "ccaa.dta", clear . . merge 1:1 _ID using "ccaa_pobreza.dta", keep(match) nogenerate noreport . . save "ccaa_pobreza_etiquetas.dta", replace file ccaa_pobreza_etiquetas.dta saved
Paso 4. Creamos los frames
correspondiente
. geoframe create ccaa using "ccaa.dta", shp("ccaa_shp.dta") replace
(creating frame ccaa from ccaa.dta)
(creating frame ccaa_shp from ccaa_shp.dta)
Frame name: ccaa [make current]
Frame type: attribute
Feature type: <none>
Number of obs: 19
Unit ID: _ID
Coordinates: _CX _CY
Linked shape frame: ccaa_shp
. geoframe create ccaa_pobreza_datos using "ccaa_pobreza_datos.dta", shp("ccaa_shp.dta") replace
(creating frame ccaa_pobreza_datos from ccaa_pobreza_datos.dta)
(creating frame ccaa_pobreza_datos_shp from ccaa_shp.dta)
(dropped 1,962 unmatched observations in frame ccaa_pobreza_datos_shp)
Frame name: ccaa_pobreza_datos [make current]
Frame type: attribute
Feature type: <none>
Number of obs: 18
Unit ID: _ID
Coordinates: _CX _CY
Linked shape frame: ccaa_pobreza_datos_shp
. geoframe create ccaa_pobreza_etiquetas using "ccaa_pobreza_etiquetas.dta", shp("ccaa_shp.dta") replace
(creating frame ccaa_pobreza_etiquetas from ccaa_pobreza_etiquetas.dta)
(creating frame ccaa_pobreza_etiquetas_shp from ccaa_shp.dta)
(dropped 1,962 unmatched observations in frame ccaa_pobreza_etiquetas_shp)
Frame name: ccaa_pobreza_etiquetas [make current]
Frame type: attribute
Feature type: <none>
Number of obs: 18
Unit ID: _ID
Coordinates: _CX _CY
Linked shape frame: ccaa_pobreza_etiquetas_shp
Paso 5. Generamos el gráfico
. geoplot ///
> (area ccaa_pobreza_etiquetas hpobreza, color(Reds) cuts(0 10 20 30 40) label("@lb - @ub", format(%09.0fc))) ///
> (label ccaa_pobreza_datos hpobreza, size(small) format(%09.1fc) color(black) ) ///
> (line ccaa, lcolor(black) lwidth(0.1)) ///
> , tight xsize(7) project legend(position(5) layout(- "Tasa de pobreza" 1) size(vsmall) col(1) reverse) ///
> title("Tasa de riesgo de pobreza en España", size(medium) margin(bottom))
(applying webmercator projection)
Obviamente, es posible realizar mapas mucho más elaborados y complicados.